【IMPORTANT】 เรียนศาสตราจารย์ Alvaro: โปรดตรวจสอบไฟล์ที่เราอัปโหลดบน Canvas ด้วย มีไฟล์โค้ด (โค้ดที่เราอัปโหลดที่นี่เป็นเหมือนบทเรียน ไม่มี prompt และข้อมูลส่วนตัว), วิดีโอสาธิต และรูปภาพรายละเอียดอื่น ๆ หรือปัญหา
โปรเจกต์ Arduino ของเราเป็นการจัดแสดงงานศิลปะที่มีหุ่นยนต์ง่าย ๆ สองตัวเป็นแกนหลัก ที่สนทนากันไม่รู้จบ พูดคุยและถกเถียงในหัวข้อต่าง ๆ เช่น ปรัชญาอัตถิภาวนิยม, มนุษยชาติ, ความรัก และอื่น ๆ วัตถุประสงค์คือเพื่อกระตุ้นความคิดและการใคร่ครวญ เสริมสร้างความอยากรู้อยากเห็นทางปัญญา ผ่านการสังเกตบทสนทนาและการสำรวจประเด็นเหล่านี้
แนวคิดเริ่มต้นมาจากการระดมสมองที่เราพิจารณาสร้างหุ่นยนต์ที่สามารถให้เสียงตอบกลับตามอินพุตของผู้ชม โดยมีเป้าหมายเพื่อนำเสนอการสนับสนุนในลักษณะที่สนุกสนานและโต้ตอบได้ อย่างไรก็ตาม หลังจากทำการวิจัยเพิ่มเติมและปรึกษาหารือ เราก็ได้แนวคิดที่น่าสนใจและสร้างสรรค์ยิ่งขึ้น เราตัดสินใจใช้ Artificial Intelligence (AI) ในการสร้างการตอบกลับและการโต้แย้ง นำไปสู่แนวคิดของหุ่นยนต์สองตัวที่สนทนากันไม่รู้จบ
เนื่องจากข้อจำกัดด้านทรัพยากรและเวลา เราจึงต้องปรับโปรเจกต์ของเราให้สำเร็จในเวอร์ชันเบื้องต้นของงานศิลปะ เราช่วยเหลือกันตลอดกระบวนการ โดย Quentin มุ่งเน้นไปที่ฟังก์ชันการสนทนา API AI text-to-speech หลัก รวมถึงส่วนประกอบฮาร์ดแวร์ (ESP32 และ Speaker) และการสร้างวิดีโอสาธิต Nielsen ทำงานในส่วนของฟังก์ชัน LED eyes, การนำเสนอ, ข้อเสนอ, รายงานที่เป็นลายลักษณ์อักษร, การวิจัยวัสดุ, การจัดหา, การผลิตวิดีโอขั้นสุดท้าย และตัวหุ่นยนต์
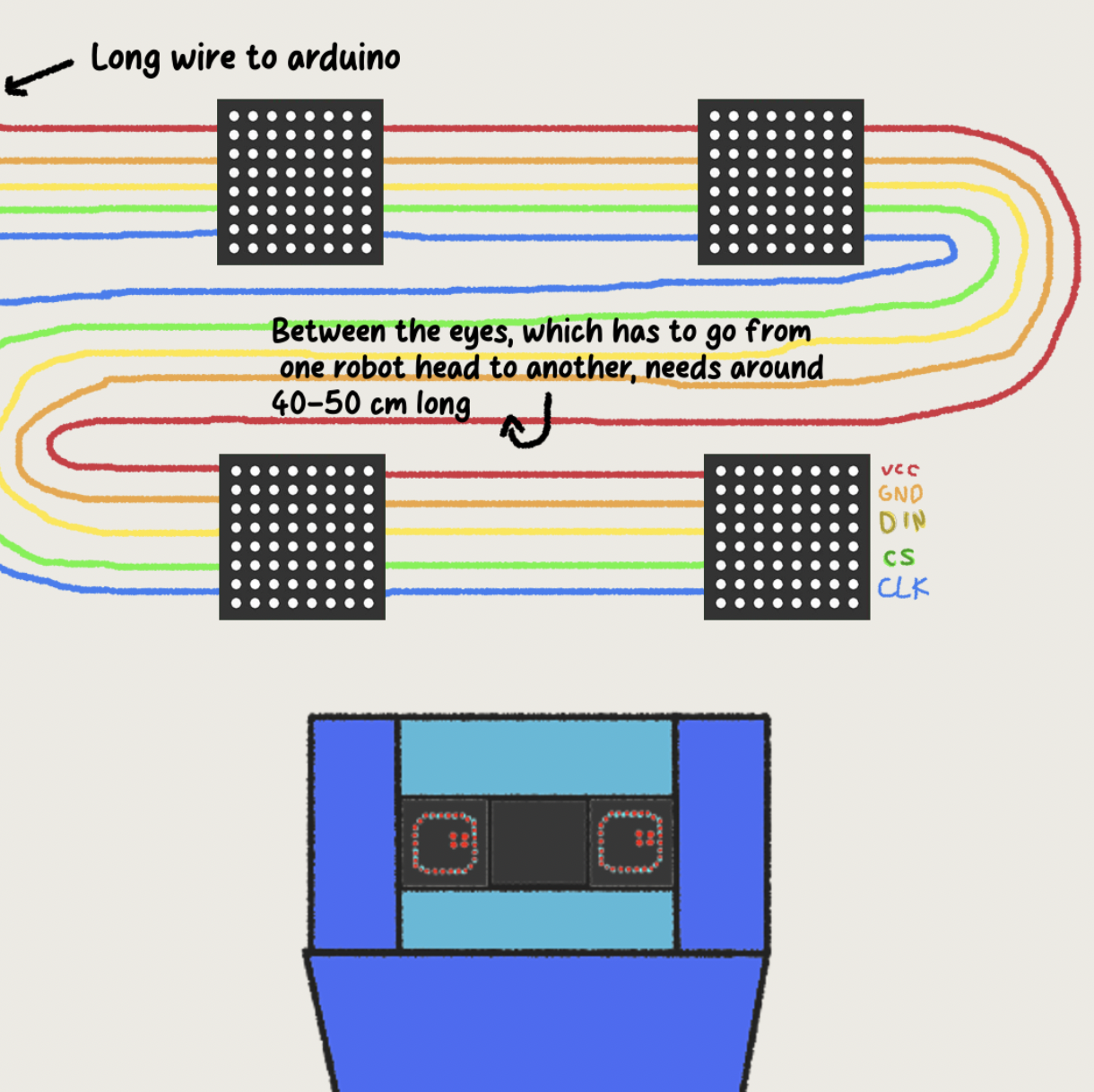
ส่วนประกอบของเรา: 1x esp32 board, 1x amplifier, 1x Speaker, 2x API (AI conversation & text to speech) , 4x LED 8x8, กระดาษแข็ง/กระดาษหนา (ตัวหุ่นยนต์) ,Arduino Kit ,สายไฟยาว 1m สำหรับระยะห่างระหว่างดวงตา โดยเฉพาะระหว่างหุ่นยนต์
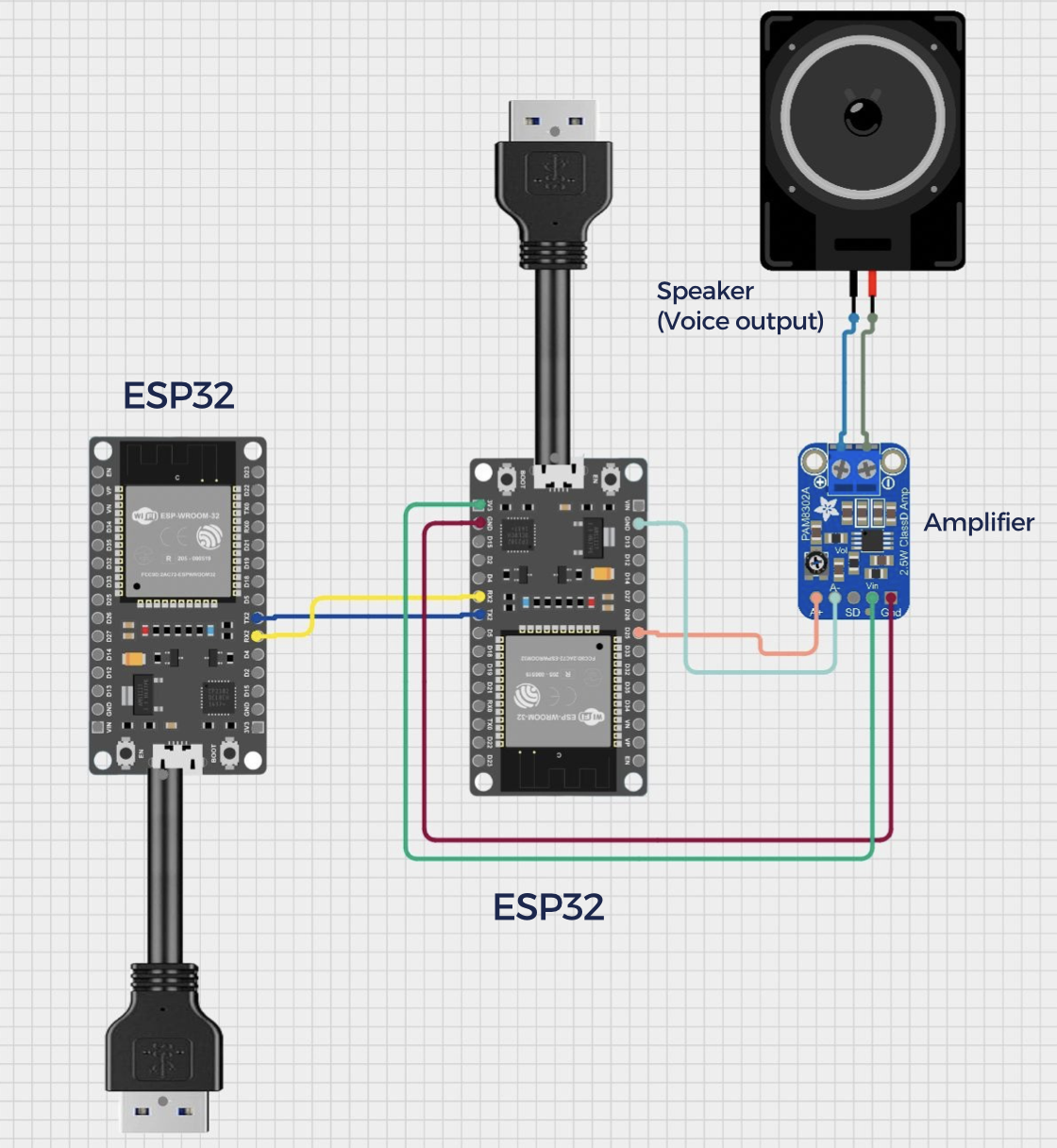

เป้าหมายของเราคือการรวมสามส่วนหลักเหล่านี้เข้าด้วยกันอย่างราบรื่น ส่วนแรกคือการสร้างบทสนทนาโดยใช้ OpenAI API ส่วนที่สองมุ่งเน้นไปที่การแปลงบทสนทนาเป็นเสียงโดยใช้เทคโนโลยี text-to-speech (TTS) ส่วนที่สามเกี่ยวข้องกับการควบคุมไฟ LED (ดวงตาของหุ่นยนต์) โดยการรวมองค์ประกอบเหล่านี้เข้าด้วยกัน เรามุ่งมั่นที่จะสร้างสรรค์งานศิลปะที่น่าดึงดูดใจซึ่งกระตุ้นความคิดและการสำรวจสำหรับผู้ชม
โค้ดถูกแบ่งออกเป็นสามส่วนหลัก ส่วนแรกคือการสร้างบทสนทนาโดยใช้ OpenAI API ส่วนที่สองคือการแปลงบทสนทนาเป็นเสียงโดยใช้ text-to-speech (TTS) ส่วนที่สามคือการควบคุมไฟ LED (ดวงตาของหุ่นยนต์)
ในระหว่างกระบวนการพัฒนา เราใช้ ESP32 ซึ่งมีฟังก์ชัน WiFi ในตัวสำหรับการส่งคำขอ API หลังจากทดสอบคำขอ API และ prompts โดยใช้ Postman ก็ได้ผลลัพธ์การตอบสนองที่สมบูรณ์ อย่างไรก็ตาม ข้อจำกัดของ API ทำให้ต้องมีการปรับเปลี่ยน ช่วงเวลาการสร้างบทสนทนาต้องตั้งไว้ที่ 20 วินาที เพื่อหลีกเลี่ยงการเกินขีดจำกัดการร้องขอ API เพื่อให้แน่ใจว่าช่วงเวลาบทสนทนาของหุ่นยนต์สุดท้ายเหมาะสม prompts ได้รับการปรับเปลี่ยนให้สร้างการตอบสนองประมาณ 10-15 วินาที เพื่อป้องกันการหยุดชั่วคราวที่นานเกินไปหรือสั้นเกินไประหว่างบทสนทนา
เมื่อโค้ดการสร้างบทสนทนาเสร็จสมบูรณ์ ขั้นตอนต่อไปคือ TTS มีการพิจารณาสองทางเลือก: การใช้ Google's Text-to-Speech API หรือการค้นหา local TTS library บน GitHub เนื่องจาก amplifier ที่เลือกคือ PAM8302 ซึ่งไม่ใช่ตัวเลือกฮาร์ดแวร์ที่เหมาะสม ตัวเลือก library ที่มีจึงถูกจำกัด
ตัวเลือกแรกคือ Google's TTS API ซึ่งให้ผลลัพธ์ที่เกือบสมบูรณ์แบบพร้อมความสามารถในการเปลี่ยนอารมณ์และโทนเสียง ทำให้ได้เสียงพูดที่เป็นธรรมชาติและคล่องแคล่วราวกับมนุษย์ อย่างไรก็ตาม ข้อเสียหลักคือค่าใช้จ่ายที่เกี่ยวข้องกับการใช้ API ซึ่งเป็นความท้าทายสำหรับนักศึกษามหาวิทยาลัยสองคน ด้วยเหตุนี้ จึงมีการตัดสินใจที่จะสำรวจตัวเลือก local library หลังจากทบทวน TTS libraries หลายตัว ก็พบสองประเภท
ประเภทแรกใช้ Google Text-to-Speech โดยไม่จำเป็นต้องใช้ API key โดยอาศัยการใช้ประโยชน์จากฟังก์ชันอ่านออกเสียงของ Google Translate ด้วยการสร้าง URL เพื่ออ่านข้อความ อย่างไรก็ตาม ความพยายามเหล่านี้ล้มเหลว น่าจะเนื่องมาจากปัญหาความเข้ากันได้กับ PAM8302 amplifier และการขาดการรองรับสำหรับ I2C interface หลังจากแก้ไขปัญหา ก็ได้เลือกวิธีการทางเลือก ซึ่งเกี่ยวข้องกับการจัดเก็บการออกเสียงของตัวอักษรภาษาอังกฤษแต่ละตัวและรวบรวมการออกเสียงคำในระหว่าง TTS วิธีนี้ไม่จำเป็นต้องมีการเชื่อมต่ออินเทอร์เน็ต ใช้หน่วยความจำน้อยลง และในตอนแรก แผนคือการใช้ ESP32 boards สองตัว (หนึ่งตัวสำหรับการสร้างข้อความและอีกตัวสำหรับ TTS) อย่างไรก็ตาม ข้อเสียคือคุณภาพเสียงที่ได้แย่มาก มีการออกเสียงที่ไม่ถูกต้องซึ่งทำให้เข้าใจเนื้อหายาก ถึงกระนั้น ก็ไม่มีทางเลือกอื่น จึงได้นำวิธีนี้มาใช้
ความท้าทายที่ใหญ่ที่สุดเกิดขึ้นหลังจากเขียนโค้ด แม้จะมั่นใจว่าฮาร์ดแวร์และโค้ดทำงานถูกต้อง แต่ TTS ก็ยังไม่ทำงาน ปัญหาคือ library ที่เลือกไม่สามารถจัดการประโยคที่ยาวกว่าหกคำได้ นี่เป็นอุปสรรคสำคัญ



เช่นเดียวกับหลาย ๆ คนที่มีความคิดสร้างสรรค์ไร้ขีดจำกัด แต่ขาดแพลตฟอร์มในการแสดงออก หุ่นยนต์สองตัวนี้จึงพูดได้เพียงคำง่าย ๆ เช่น "hello" และ "hi" ในฐานะนักศึกษามหาวิทยาลัยสองคน เราตัดสินใจว่าหากวันหนึ่งเรามีฐานะร่ำรวยหรือคิดค้นวิธีแก้ปัญหาใหม่ได้ เราจะทำให้โปรเจกต์นี้สมบูรณ์และสมบูรณ์แบบ :)
แหล่งอ้างอิง-แนวคิด:
1.Amplifier & Voice Output: https://www.youtube.com/watch?v=SCAKQsGt9wI
2.LED 8X8: https://www.youtube.com/watch?v=2rZWN1IcZpA&t=359s
3.API reference: https://www.youtube.com/watch?v=23_ttll2EWU
4.Text to Speech library: https://github.com/jscrane/TTS
รายละเอียดทางเทคนิคเพิ่มเติม
พฤติกรรมการสร้างสรรค์
"Artificial Existences" สำรวจแนวคิดของชีวิตดิจิทัลและการเคลื่อนที่แบบอัตโนมัติ
- Algorithm พฤติกรรม: ใช้โมเดลทางคณิตศาสตร์เช่น Boids (flocking behavior) หรือ Cellular Automata ที่ถูกนำมาใช้ใน Arduino firmware เพื่อสร้างรูปแบบแสงหรือการเคลื่อนไหวที่คาดเดาไม่ได้และดูเป็นธรรมชาติ
- การรับข้อมูลจาก Sensor: Environmental sensors (Light, Sound, หรือ Proximity) ทำหน้าที่เป็น "สิ่งกระตุ้น" สำหรับสิ่งมีชีวิตดิจิทัลเหล่านี้ โดยส่งผลต่อสถานะภายในและพฤติกรรมที่เกิดขึ้น
การทำให้เป็นฮาร์ดแวร์
การ "ดำรงอยู่" มักจะปรากฏให้เห็นผ่าน NeoPixel (W