ในบทเรียนนี้เราจะเก็บข้อมูลจากไมโครโฟนเพื่อดึงข้อมูลเพลงเป็นช่วงๆ แล้วใช้ NanoEdge AI Studio (เครื่องมือฟรี) ในการสร้างโมเดล AI ที่สามารถจำแนกเพลงของเราได้อัตโนมัติ
ไม่ต้องกังวลไป น้องไม่ต้องมีความรู้เรื่อง AI ก็ทำตามได้สบายๆ :)
แผนการมีดังนี้:
- ขั้นตอนที่ 1: เตรียมการตั้งค่า
- ขั้นตอนที่ 2: เก็บข้อมูลจากไมโครโฟน
- ขั้นตอนที่ 3: สร้างโมเดล Classification
- ขั้นตอนที่ 4: เพิ่มโมเดลลงในโค้ด Arduino ของเรา
- ขั้นตอนที่ 5: ใช้ LED Matrix แสดงผลเพลงที่ตรวจจับได้
จัดไปวัยรุ่น!
ขั้นตอนที่ 1: เตรียมการตั้งค่า

อย่างแรก เราต้องเชื่อมต่อไมโครโฟนเข้ากับบอร์ด Arduino ก่อน
ใช้สายจัมเปอร์เชื่อมต่อดังนี้:
- OUT (ไมค์) ไปที่ A0 (บอร์ด)
- GND ไปที่ขา GND ใดก็ได้บนบอร์ด
- VCC ไปที่ 3.3v
ตรวจสอบให้แน่ใจว่ามีสาย USB เชื่อมต่อบอร์ดกับคอมพิวเตอร์อยู่
ใน Arduino IDE:
ตรวจสอบว่าเลือกพอร์ต COM ถูกต้อง: Tools > Port แล้วเลือกอันที่ถูกต้อง
เลือกบอร์ดให้ถูกต้อง:
- Tools > Boards > Arduino Renesas UNO R4 boards > Arduino UNO R4 WIFI
- ถ้าไม่เจอ ให้คลิก Tools > Boards > Boards Manager..., หา UNO R4 แล้วติดตั้งแพ็คเกจ
ขั้นตอนที่ 2: บันทึกข้อมูลด้วยไมโครโฟน
เราใช้ไมโครโฟนดิจิทัลที่มีอัตราข้อมูลสูงมาก
เราจะเก็บข้อมูลเพลงเป็นช่วงๆ โดยเก็บค่าจากไมโครโฟนลงในบัฟเฟอร์ และลดอัตราข้อมูลลงโดยเก็บเพียง 1 ค่าจากทุกๆ 32 ค่าที่อ่านได้
เราเก็บบัฟเฟอร์ของเพลง ไม่ใช่เก็บโน้ตเดี่ยวๆ เพื่อนำไปจำแนก แม้แต่คนเรายังจำเพลงจากโน้ตสุ่มๆ โน้ตเดียวไม่ได้เลย
วิธีการทำ:
- กำหนด AMP_PIN เป็น A0 เพราะไมค์ของเราใช้พิน A0 ส่งข้อมูล
- เรากำหนดบัฟเฟอร์ชื่อ neai_buffer เพื่อเก็บค่าที่อ่านได้
- ในกรณีนี้ บัฟเฟอร์มีขนาด 1024 (SENSOR_SAMPLE)
- เราเริ่มต้น Serial ในฟังก์ชัน setup()
- เราสร้างฟังก์ชัน get_microphone_data() เพื่อเก็บข้อมูลจากไมค์เป็นบัฟเฟอร์ โดยเก็บแค่ 1 ใน 32 ค่า
- เราพิมพ์ค่าบัฟเฟอร์ออกมาเพื่อส่งผ่าน Serial
โค้ด:
/* Defines ----------------------------------------------------------*/
#define SENSOR_SAMPLES 1024 //buffer size
#define AXIS 1 //microphone is 1 axis
#define DOWNSAMPLE 32 //microphone as a very high data rate, we downsample it
/* Prototypes ----------------------------------------------------------*/
void get_microphone_data(); //function to collect buffer of sound
/* Global variables ----------------------------------------------------------*/
static uint16_t neai_ptr = 0; //pointers to fill for sound buffer
static float neai_buffer[SENSOR_SAMPLES * AXIS] = {0.0}; //souhnd buffer
int const AMP_PIN = A0; // Preamp output pin connected to A0
/* Setup function ----------------------------------------------------------*/
void setup() {
Serial.begin(115200);
delay(10);
}
/* Infinite loop ----------------------------------------------------------*/
void loop() {
get_microphone_data();
}
/* Functions declaration ----------------------------------------------------------*/
void get_microphone_data()
{
static uint16_t temp = 0; //stock values
int sub = 0; //increment to downsample
//while the buffer is not full
while (neai_ptr < SENSOR_SAMPLES) {
//we only get a value every DOWNSAMPLE (32 in this case)
if (sub > DOWNSAMPLE) {
/* Fill neai buffer with new accel data */
neai_buffer[neai_ptr] = analogRead(AMP_PIN);
/* Increment neai pointer */
neai_ptr++;
sub = 0; //reset increment
}
else {
//we read the sample even if we don't use it
//else it is instantaneous and we don't downsample
temp = analogRead(AMP_PIN);
}
sub ++;
}
//print the buffer values to send them via serial
for (uint16_t i = 0; i < SENSOR_SAMPLES; i++) {
Serial.print(neai_buffer[i]);
Serial.print(" ");
}
Serial.print("\n");
neai_ptr = 0; //reset the beginning position
}
วิธีใช้โค้ดนี้ก็แค่ก๊อปวางลงใน Arduino IDE ถ้าน้องทำตามขั้นตอนตั้งค่าแล้ว ก็แค่กด UPLOAD (ลูกศรเล็กๆ ด้านบน) ได้เลย
ในขั้นตอนต่อไป เราจะใช้โค้ดนี้เก็บข้อมูลใน NanoEdge AI Studio และสร้าง AI Library ไว้จำแนกเพลง
ขั้นตอนที่ 3: โมเดล Classification
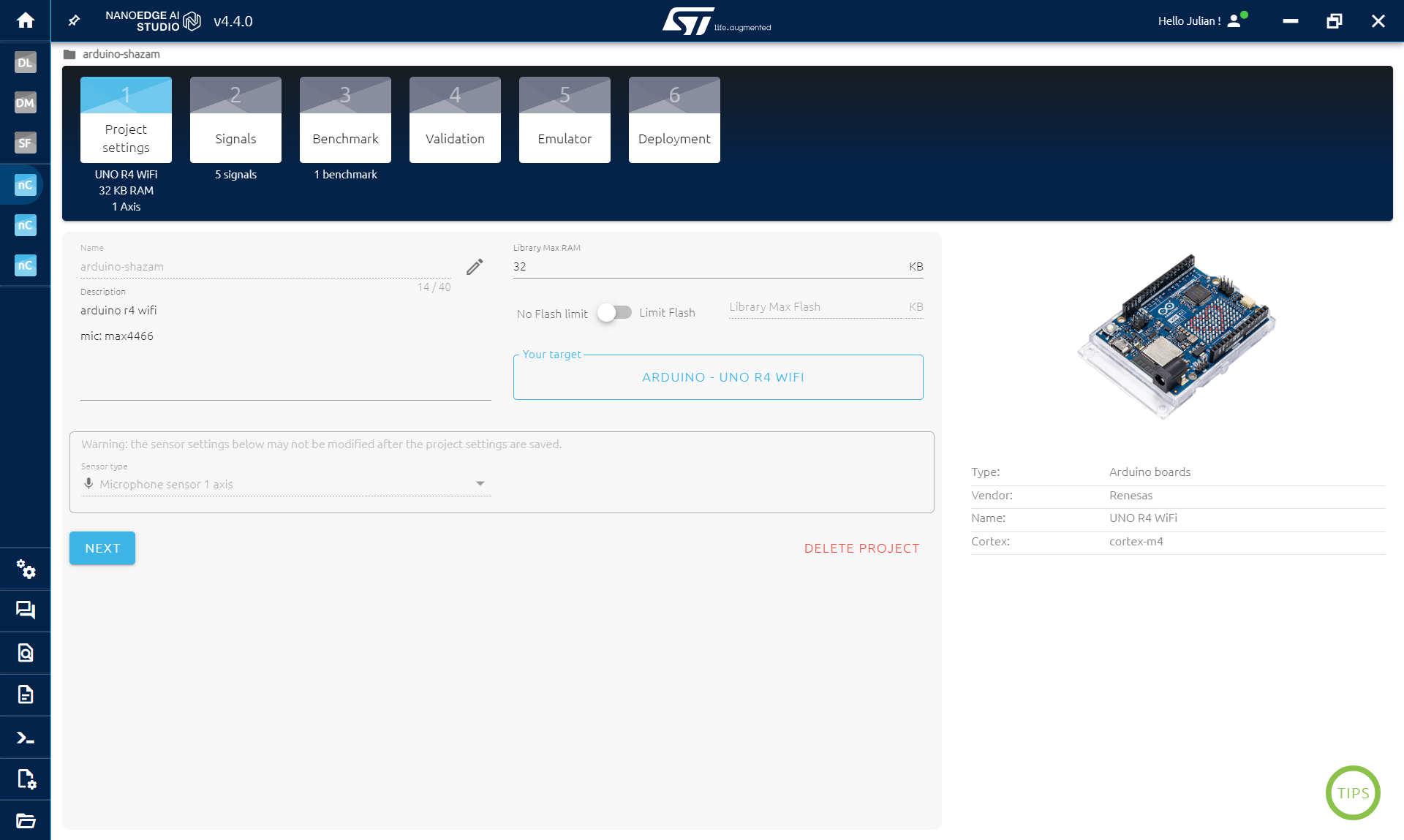
ด้วยโค้ดจากขั้นตอนที่แล้ว เราสามารถใช้ NanoEdge เก็บชุดข้อมูลสำหรับเพลงแต่ละเพลงที่เราอยากจำแนกได้:
- เปิด NanoEdge
- สร้างโปรเจค N-class classification
- เลือกบอร์ด Arduino R4 WIFI เป็นเป้าหมาย (บอร์ดอื่นก็ใช้ได้)
- เลือก Microphone 1axis เป็นเซ็นเซอร์
- คลิก Next
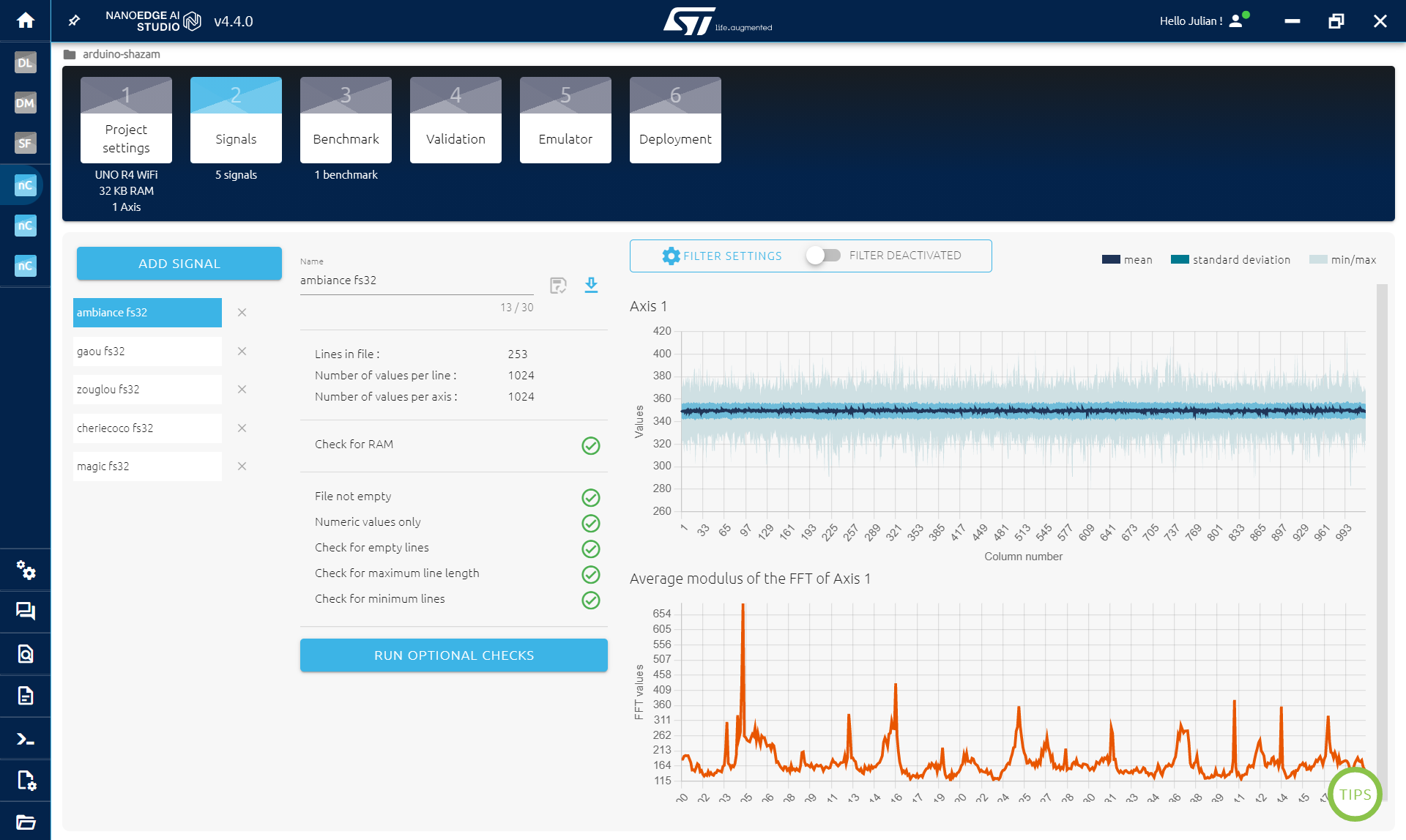
จากนั้นเราจะเก็บข้อมูลสำหรับแต่ละเพลง ในขั้นตอน SIGNAL STEP:
- คลิก ADD SIGNAL
- เลือก FROM SERIAL (USB)
- เปิดเพลงก่อน (เช่นจากโทรศัพท์)
- จากนั้นคลิก START/STOP เพื่อเก็บข้อมูล (ตรวจสอบว่าเลือกพอร์ต COM ถูกต้อง)
- เก็บบัฟเฟอร์ขณะที่เพลงเล่นอย่างน้อยสองรอบ หลีกเลี่ยงบัฟเฟอร์ว่าง (หยุดเก็บถ้าจำเป็น)
- คลิก CONTINUE แล้ว IMPORT
- เปลี่ยนชื่อไฟล์ได้ถ้าอยาก
- ทำซ้ำสำหรับแต่ละเพลง
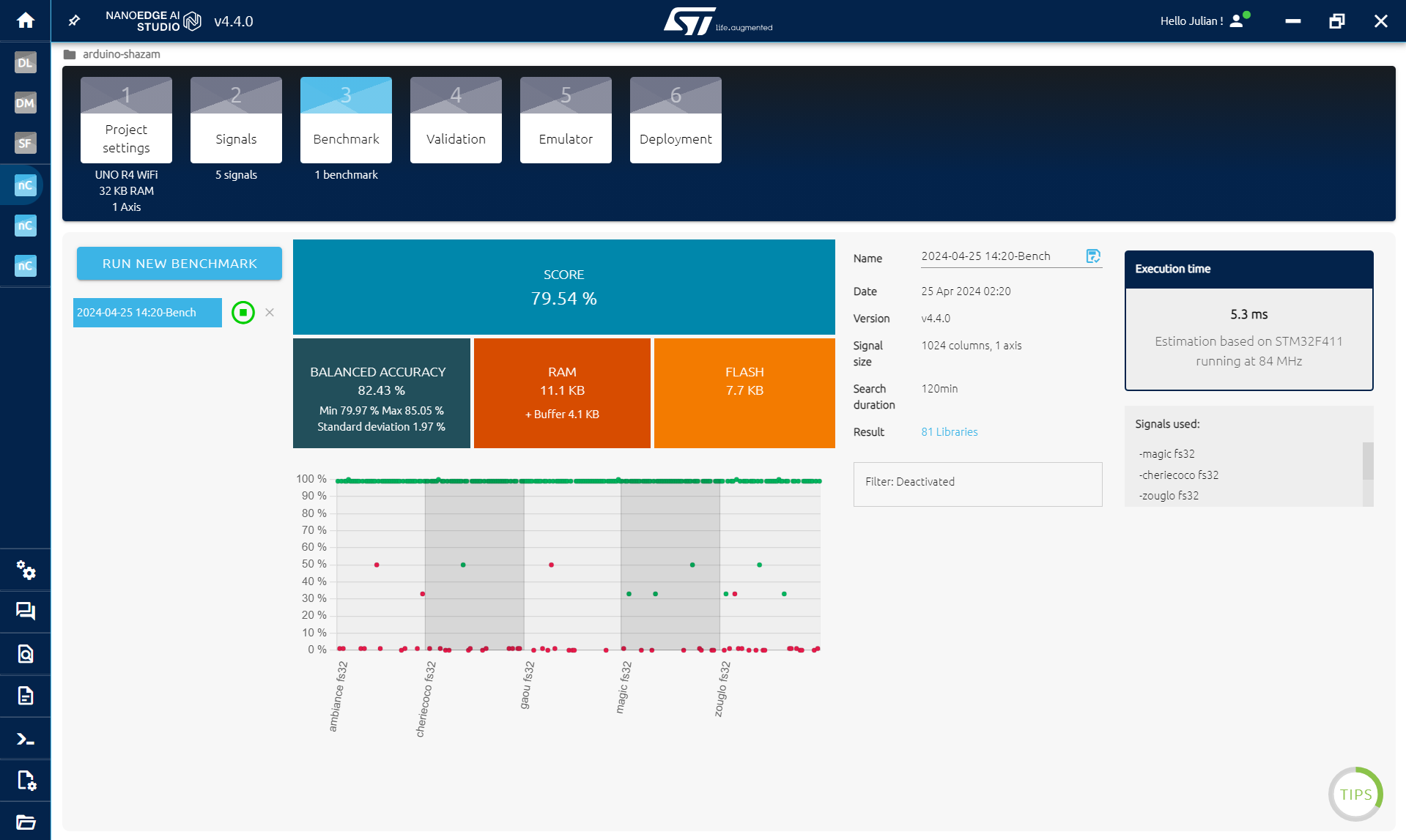
เมื่อเก็บข้อมูลทุกเพลงที่ต้องการแล้ว ไปที่ขั้นตอน BENCHMARK STEP
ยิ่งมีเพลงเยอะ ยิ่งยากขึ้น เริ่มจากเพลงน้อยๆ ก่อนนะ
- คลิก NEW BENCHMARK
- เลือกเพลงทั้งหมดแล้วคลิก START
Benchmark จะหาค่าที่ดีที่สุดของโมเดลและวิธีประมวลผลข้อมูล เพื่อหาโมเดลที่สามารถจำแนกเพลงได้
ภายในไม่กี่สิบนาที น้องควรได้คะแนน > 80% ถ้าไม่ถึง อาจต้องกลับไปขั้นตอนก่อนหน้าและเก็บข้อมูลใหม่ด้วยบัฟเฟอร์ที่ยาวขึ้นหรือค่า downsample ที่มากขึ้น แบบนี้:
/* Defines ----------------------------------------------------------*/
#define SENSOR_SAMPLES 2048 //buffer size
#define DOWNSAMPLE 64 //microphone as a very high data rate, we downsample it
แล้วทำกระบวนการทั้งหมดซ้ำใหม่
ขั้นตอนเสริม (Optional):
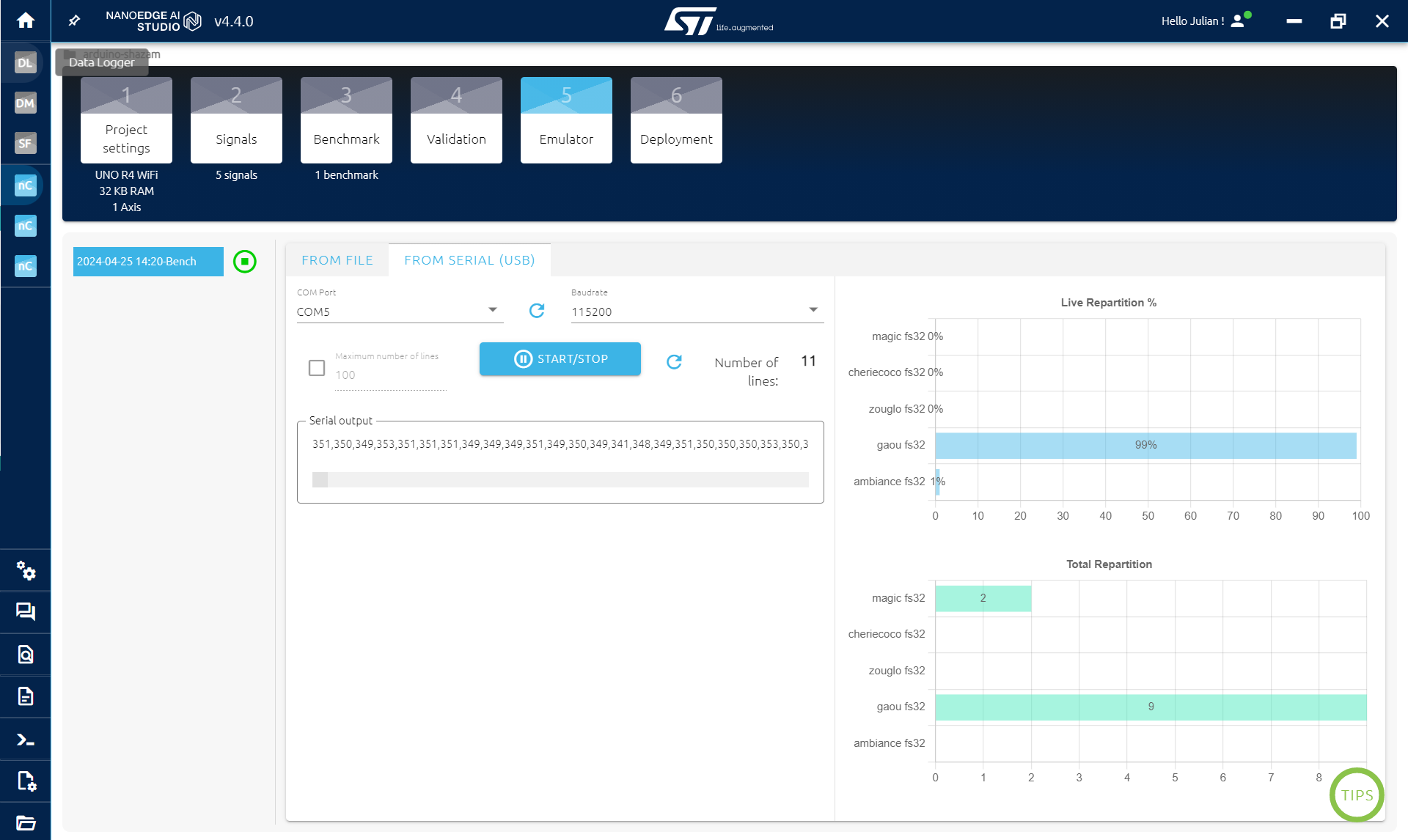
ไปที่ EMULATOR STEP เพื่อทดสอบว่าโมเดลทำงานได้จริง:
- คลิก INIATILIZE EMULATOR
- คลิก SERIAL (USB)
- คลิก START/STOP ขณะที่เปิดเพลง
สิ่งที่เห็นด้านขวาบนคือความน่าจะเป็นที่ข้อมูลจะเป็นของแต่ละคลาส ถ้าโมเดลทำงาน ค่าความน่าจะเป็นสูงสุดควรตรงกับเพลงที่กำลังเล่นอยู่ อาจสลับไปมาบ้างเป็นบางครั้ง
ด้านขวาล่างคือแค่การนับจำนวนคลาสที่ถูกตรวจจับ (คลาสที่มีความน่าจะเป็นสูงสุดด้านบนจะถูกเลือกเป็นคลาสที่ตรวจจับได้)
จากนั้นไปที่ COMPILATION STEP:
คลิก compile กรอกฟอร์มเล็กน้อย แล้วบันทึก AI library (.zip) ของน้องไว้
ในขั้นตอนต่อไป เราจะเพิ่มไลบรารีนี้เข้าไปใน Arduino IDE เพื่อจำแนกเพลงบนบอร์ดได้โดยตรง
รายละเอียดเทคนิคเพิ่มเติม: กระบวนการ TinyML
โปรเจค Automatic Song Classification นี่แหละ ที่จะพาไมโครคอนโทรลเลอร์ของเราไปเล่นในแดน AI ให้เห็นกันจะๆ ต่างจาก Spectrum Analyzer ทั่วไปที่แค่วัดเสียงเบสไปวันๆ ระบบนี้ใช้ Neural Network (TinyML) ที่เทรนไว้แล้วมาจับแพทเทิร์นในเสียงเพลง แยกแยะออกเลยว่าเพลงไหนเป็นเพลงไหน
น้องจะเขียน `if/else` แบบธรรมดามาตรวจสอบไม่ได้หรอก ต้องเทรนโมเดลเท่านั้น! กระบวนการมันก็คือ เก็บข้อมูล, เทรนโมเดล, แล้วเอาโมเดลไปรันแบบเรียลไทม์
1. เก็บข้อมูลเสียง (The Dataset)
- ฮาร์ดแวร์: ถ้าอยากได้ผลลัพธ์ดีๆ แนะนำให้ใช้ไมโครโฟนดิจิตอล I2S ที่ความไวสูง (เช่น INMP441) ต่อกับบอร์ดอย่าง ESP32 หรือ Arduino Nano 33 BLE Sense เพื่อเก็บข้อมูลคุณภาพสูง แต่ถ้าใช้เซ็ตอัพไมโครโฟนอนาล็อกแบบในรูปก็ใช้ได้กับ Arduino UNO R4 WiFi ตามเวิร์กโฟลว์ของ NanoEdge AI Studio นะ
- การเก็บตัวอย่าง: น้องก็เปิดเพลงที่อยากให้ระบบจำแนก แล้วให้ไมโครโฟนฟัง ไมโครคอนโทรลเลอร์จะแปลงคลื่นเสียงดิบๆ ให้กลายเป็นข้อมูลตัวเลข (หรือในขั้นสูงหน่อยก็แปลงเป็นคุณลักษณะอย่าง Mel-Frequency Cepstral Coefficients (MFCCs) – ซึ่งเป็นภาพแสดงความถี่เสียงแบบกะทัดรัดเมื่อเวลาผ่านไป)
2. เทรนโมเดลด้วย NanoEdge AI Studio
น้องก็อัพโหลดข้อมูลตัวเลขที่เก็บมา ขึ้นไปบน NanoEdge AI Studio ตามที่เห็นในรูปด้านบน
- อัลกอริทึม Benchmark ของแพลตฟอร์มจะวิเคราะห์ข้อมูลจากแต่ละคลาสเพลงอัตโนมัติ มันจะหาวิธีประมวลผลสัญญาณและโมเดล Machine Learning (เช่น Neural Network) ที่ดีที่สุด เพื่อเรียนรู้แพทเทิร์นเฉพาะที่ทำให้เสียงของเพลงหนึ่งต่างจากอีกเพลง
- พอเทรนเสร็จ NanoEdge AI Studio จะให้ไลบรารีภาษา C/C++ ที่คอมไพล์แล้ว (`NanoEdgeAI.h` และ `knowledge.h`) มาเลย พิเศษสำหรับบอร์ด Arduino ของน้องโดยเฉพาะ!
3. การทำนายแบบเรียลไทม์ (Real-Time Inference)
- สมองกล: น้องก็เอาไลบรารีที่ได้มา ไปใส่ใน Arduino IDE แล้วอัพโหลดสเก็ตช์สุดท้ายลงบอร์ด
- พอเปิดเพลงในห้อง ไมโครโฟนจะบันทึกเสียงช่วงสั้นๆ (Buffer) ไว้
- ไลบรารี AI บนบอร์ดจะคำนวณการจำแนกเพลงแบบ Local เลย (ไม่ต้องใช้เน็ต) แล้วส่งผลลัพธ์ออกมา เช่น ไปที่ Serial Monitor หรือ LED Matrix นั่นแหละ Arduino ของเราก็จำแนกเพลงได้ด้วยคณิตศาสตร์ TinyML แล้วไง!
ขั้นตอนที่ 4: เอาไลบรารี Classification มาใช้
ได้ไลบรารีมาแล้ว ต่อไปก็ต้องเอามาใส่ในโค้ด Arduino ของเรา:
- เปิดไฟล์ .zip ที่ได้มา จะมีโฟลเดอร์ Arduino ที่ข้างในมี zip อีกอัน
- นำเข้าไลบรารีใน Arduino IDE: Sketch > Include library > Add .ZIP library... แล้วเลือกไฟล์ .zip ที่อยู่ในโฟลเดอร์ Arduino
**ถ้าน้องใช้ไลบรารี NanoEdge AI อยู่ใน Arduino IDE อยู่แล้ว:**
ให้เข้าไปที่ document/arduino/library แล้วลบไลบรารีเก่าของ NanoEdge ออก จากนั้นค่อยทำตามขั้นตอนด้านบนเพื่อนำเข้าไลบรารีใหม่
**สำคัญมาก:**
ถ้าเจอ Error เรื่อง RAM นั่นอาจเป็นเพราะไลบรารีจาก NanoEdge ใหญ่เกิน ให้กลับไปที่ขั้นตอน VALIDATION ใน NanoEdge แล้วเลือกไลบรารีขนาดเล็กลง (คลิกที่มงกุฎด้านขวา) จากนั้นคอมไพล์ใหม่แล้วเอามาแทนที่ใน Arduino IDE อีกที
คัดลอกโค้ดด้านล่างไปวางใน Arduino IDE ได้เลย มันมีโค้ดจากก่อนหน้ารวมอยู่แล้ว และมีทุกอย่างที่ต้องใช้สำหรับ NanoEdge:
- การเรียกใช้ไลบรารี
- ตัวแปรบางตัวสำหรับ NanoEdge
- การตั้งค่าเริ่มต้นไลบรารีในฟังก์ชัน setup
- การจำแนกประเภทหลังจากเก็บข้อมูลเสียง
- การแสดงผลคลาส
/* Libraries ----------------------------------------------------------*/
#include "NanoEdgeAI.h"
#include "knowledge.h"
/* Defines ----------------------------------------------------------*/
#define SENSOR_SAMPLES 1024 //buffer size
#define AXIS 1 //microphone is 1 axis
#define DOWNSAMPLE 32 //microphone as a very high data rate, we downsample it
/* Prototypes ----------------------------------------------------------*/
void get_microphone_data(); //function to collect buffer of sound
/* Global variables ----------------------------------------------------------*/
static uint16_t neai_ptr = 0; //pointers to fill for sound buffer
static