เป้าหมายของบทเรียนนี้คือการตรวจจับว่าเครื่องชงกาแฟกำลังจะน้ำหมด ก่อนที่มันจะเกิดขึ้นจริง เพราะการใช้งานปั๊มของเครื่องโดยไม่มีน้ำอาจทำให้มันพังได้น้า
เราจะทำแบบไม่ต้องไปยุ่งกับตัวเครื่องเลย (non-intrusive) แค่เอา Arduino พร้อมกับ accelerometer ไปแปะไว้บนเครื่องก็พอ
เราจะใช้ NanoEdge AI Studio (ฟรีนะจ๊ะ) ในการสร้างโมเดล AI ที่สามารถแยกแยะได้ว่า... อ้าว ผิดบท! โมเดลนี้เอาไว้แยกเสียงออดกับเสียงรบกวน แต่หลักการเดียวกันเลย ฮ่าๆ
ไม่ต้องกลัวว่าไม่รู้เรื่อง AI นะ น้องทำตามพี่ได้แน่ :)
ภาพรวมโปรเจค
"Coffee-Sense" นี่คือการประยุกต์ใช้ Embedded Edge-AI Forensics และ Mechatronic Vibrational Diagnostics แบบสุดล้ำน้า! แทนที่จะใช้เซ็นเซอร์วัดระดับน้ำที่ต้องไปเจาะถัง (ยุ่งยาก) เราใช้แค่ accelerometer แปะไว้ แล้วฟัง "จังหวะ" การสั่นของปั๊มน้ำข้างในเครื่องแทน
พอปั๊มเริ่มทำงานโดยไม่มีน้ำ มันจะสั่นคนละแบบ (มี "Signature" เป็นของตัวเอง) ระบบเราก็จะตรวจจับความแตกต่างนี้ได้ แล้วส่งสัญญาณเตือนให้เรารู้ล่วงหน้า เรียกว่าเอา Machine Learning มาใช้ในชีวิตประจำวันแบบไม่ต้องพังเครื่องเลยสักนิด!
ขั้นตอนที่ 1: เตรียมตัว
เริ่มจากเสียบชีลด์ของ STMicroelectronics เข้ากับบอร์ด Arduino แล้วใช้ Blu-Tack (หรือกาวสองหน้าแบบนิ่มๆ) แปะบอร์ดทั้งหมดไว้บนตัวเครื่องชงกาแฟเลย


ใน Arduino IDE: ตรวจสอบให้แน่ใจว่าเลือกพอร์ต COM ถูก: Tools > Port แล้วเลือกอันที่ตรงกับบอร์ดเรา เลือกบอร์ดให้ถูกต้อง:
- Tools > Boards > Arduino Renesas UNO R4 boards > Arduino UNO R4 WIFI
- ถ้าไม่เห็น ให้คลิก Tools > Boards > Boards Manager... แล้วค้นหา UNO R4 เพื่อติดตั้ง package
ขั้นตอนที่ 2: เก็บข้อมูลจาก Accelerometer
เราใช้ STMicroelectronics X-NUCLEO-ISK01A3 เพราะมันมี LSM6DSO นะ ถ้าน้องมี accelerometer ตัวอื่นก็ใช้แทนได้
เพื่อให้ได้โค้ดสำหรับดึงข้อมูล (datalogging) เราจะใช้เครื่องมือใน NanoEdge AI Studio มาสร้างให้เลย
- เปิด NanoEdge AI Studio
- ไปที่ Data logger Generator
- เลือก Arduino
- เลือกเซ็นเซอร์เป็น LSM6DSO
- ตั้งค่า data rate สูงสุด (1667Hz), range เป็น 8 และ buffer size เป็น 512
- คลิก Generate Data Logger
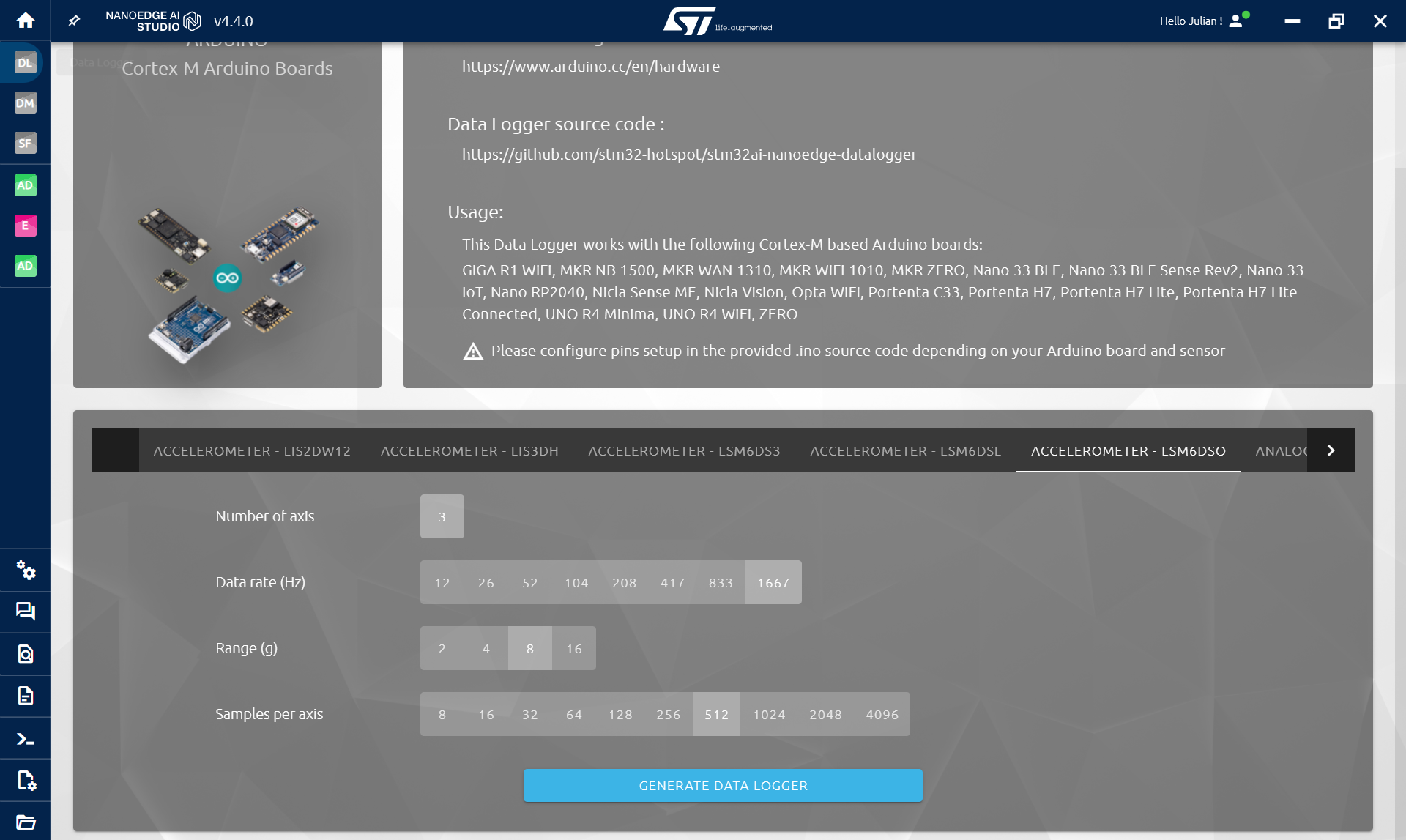
NanoEdge จะสร้างไฟล์ .zip ออกมา ซึ่งข้างในมีไฟล์ .ino ที่เรานำไปใช้กับ Arduino IDE ได้ทันที:
- แยกไฟล์ .zip แล้วเปิดไฟล์ .ino
- Import library ที่จำเป็น (Wire และ STM32duino LSM6DSO) แล้วอัพโหลดโค้ดลงบอร์ดได้เลย
โค้ดตัวอย่างอยู่ด้านล่างในชื่อ main_datalogging.c
โค้ดที่ได้มาจะมีส่วนที่ถูก comment ไว้สำหรับไลบรารีของ NanoEdge AI อยู่ เราจะกลับมาใช้ส่วนนี้ทีหลัง หลังจากที่สร้างโมเดลเสร็จแล้วน้า
ลงลึกกันแบบช่างๆ
- นิติวิทยาศาสตร์ความสั่นสะเทือน (Vibrational Anomaly Forensics):
- ลายเซ็นฮาร์มอนิกของปั๊ม (Pump Harmonic Signature): ปั๊มไฟฟ้าจะแสดงรูปแบบการสั่นพ้องเชิงกล (mechanical resonance) ที่แตกต่างกันไป ขึ้นอยู่กับภาระ (มีของไหลหรือเปล่า) พอถังน้ำหมด ปั๊มจะเข้าสู่สภาวะสั่นสะเทือนความถี่สูงและมีการหน่วงต่ำ เซ็นเซอร์วัดความเร่ง LSM6DSO จะสุ่มเก็บค่าพิกัด $(X, Y, Z)$ แบบ 3 มิติ ด้วยอัตราสูง $(1667\text{Hz})$ เพื่อจับ "อาการสั่นกระตุกเล็กๆ (Jitter)" ที่เกิดขึ้นตอนที่ของไหลหมด
- การประมวลผลข้อมูลด้วย FFT (FFT Data-Preprocessing): ระบบจัดการกับข้อมูลดิบขนาด 512 ตัวอย่าง โดยทำการแปลงฟูริเยร์แบบเร็ว (FFT) เพื่อเปลี่ยนการสั่นสะเทือนที่วัดได้ตามเวลา ให้เป็นความหนาแน่นของสเปกตรัมกำลังในโดเมนความถี่ วิธีนิติวิทยาศาสตร์แบบนี้ทำให้ AI ของเราสามารถแยกแยะระหว่าง "เสียงทำงานปกติ (Nominal Grind)" กับ "อาการทำงานแห้งๆ แบบผิดปกติ (Abnormal Dry-Run)" ของเครื่องได้
- การควบคุม NanoEdge AI:
- ฮิวริสติกการเรียนรู้บนอุปกรณ์ (On-Device Learning Heuristics): Coffee-Sense ใช้เอ็นจิ้นตรวจจับความผิดปกติ (Anomaly Detection - AD) ของ NanoEdge AI สถาปัตยกรรมนี้ไม่เหมือนโมเดลแบบตายตัว มันทำให้ Arduino R4 ของเรา "เรียนรู้" โปรไฟล์การสั่นสะเทือนเฉพาะของเครื่องชงกาแฟของผู้ใช้ในสภาพแวดล้อมจริงได้เลย กระบวนการนี้เกี่ยวข้องกับการคำนวณ "คะแนนความคล้ายคลึง (Similarity Score)" $(0\text{--}100)$; ถ้าคะแนน $>90$ แปลว่าทำงานปกติ แต่ถ้าคะแนนดิ่งฮวบฮาบเมื่อไหร่ นั่นคือสัญญาณเตือนให้เติมน้ำแล้วจ้า!
- การปรับแต่งไลบรารี่เป้าหมาย (Target-Library Optimization): โมเดล AI นี้ถูกคอมไพล์มาเฉพาะสำหรับแกน Renesas RA4M1 เพื่อให้ใช้พื้นที่ RAM และ FLASH ได้อย่างคุ้มค่า และทำให้บัสเซ็นเซอร์ที่รับข้อมูลเร็วๆ ไม่ต้องมาคอยเพราะการประมวลผลล่าช้า
ขั้นตอนที่ 3: NanoEdge AI Studio
NanoEdge AI Studio เป็นซอฟต์แวร์ฟรีจาก STMicroelectronics ช่วยให้ผู้ใช้ระบบฝังตัวสร้างโมเดล AI ได้ง่ายขึ้น และบอกเลยว่าใช้ง่ายมาก:
- เลือกประเภทโปรเจค
- นำเข้าข้อมูล
- รับโมเดลที่ดีที่สุดจากข้อมูลของคุณ
- ทดสอบมัน
- คอมไพล์และใช้งานด้วยฟังก์ชันไม่กี่อัน
สำหรับเรา เราจะทำโปรเจคตรวจจับความผิดปกติ (Anomaly detection - AD) เราอยากตรวจจับสถานการณ์ปกติ (ตอนมีน้ำชงกาแฟ) และสถานการณ์ผิดปกติ (ตอนน้ำหมด) เราอาจจะทำโมเดลจำแนกหลายคลาส (N-class classification) ก็ได้ แต่เก็บไว้พูดท้ายๆ แล้วกัน
ในส่วน Project Settings:
- ตั้งชื่อโปรเจค
- เลือกเป้าหมายเป็น Arduino R4 Wifi
- เลือกเซ็นเซอร์: Accelerometer 3 แกน
- กำหนดขีดจำกัด FLASH และ RAM (สำหรับการค้นหาโมเดล) ก็ได้ถ้าต้องการ
ในส่วน Regular signals: ตรงนี้เราจะบันทึกสัญญาณปกติ ซึ่งในกรณีของเราคือตอนที่เครื่องชงกาแฟมีน้ำพอสำหรับชง คุณสามารถนำเข้าข้อมูลที่มีอยู่แล้ว (ไฟล์ .txt หรือ .csv) หรือบันทึกข้อมูลตรงใน NanoEdge เลยก็ได้
- สิ่งที่เราอยากบันทึกคือตอนที่เครื่องกำลังชงกาแฟ
- หลีกเลี่ยงสัญญาณว่างเปล่า (ตอนเครื่องไม่ทำอะไรเลย)
- เก็บข้อมูลให้ได้ประมาณ 50 ถึง 100 บัฟเฟอร์
วิธีบันทึกข้อมูลใน NanoEdge โดยตรง:
- คลิก ADD SIGNAL
- เลือก FROM SERIAL (USB)
- คลิก START/STOP เพื่อเริ่มเก็บข้อมูล (ตรวจสอบให้แน่ใจว่าเลือกพอร์ต COM ถูกต้อง)
- พอเสร็จแล้ว คลิก CONTINUE แล้วตามด้วย IMPORT
- เปลี่ยนชื่อไฟล์ได้ถ้าอยาก
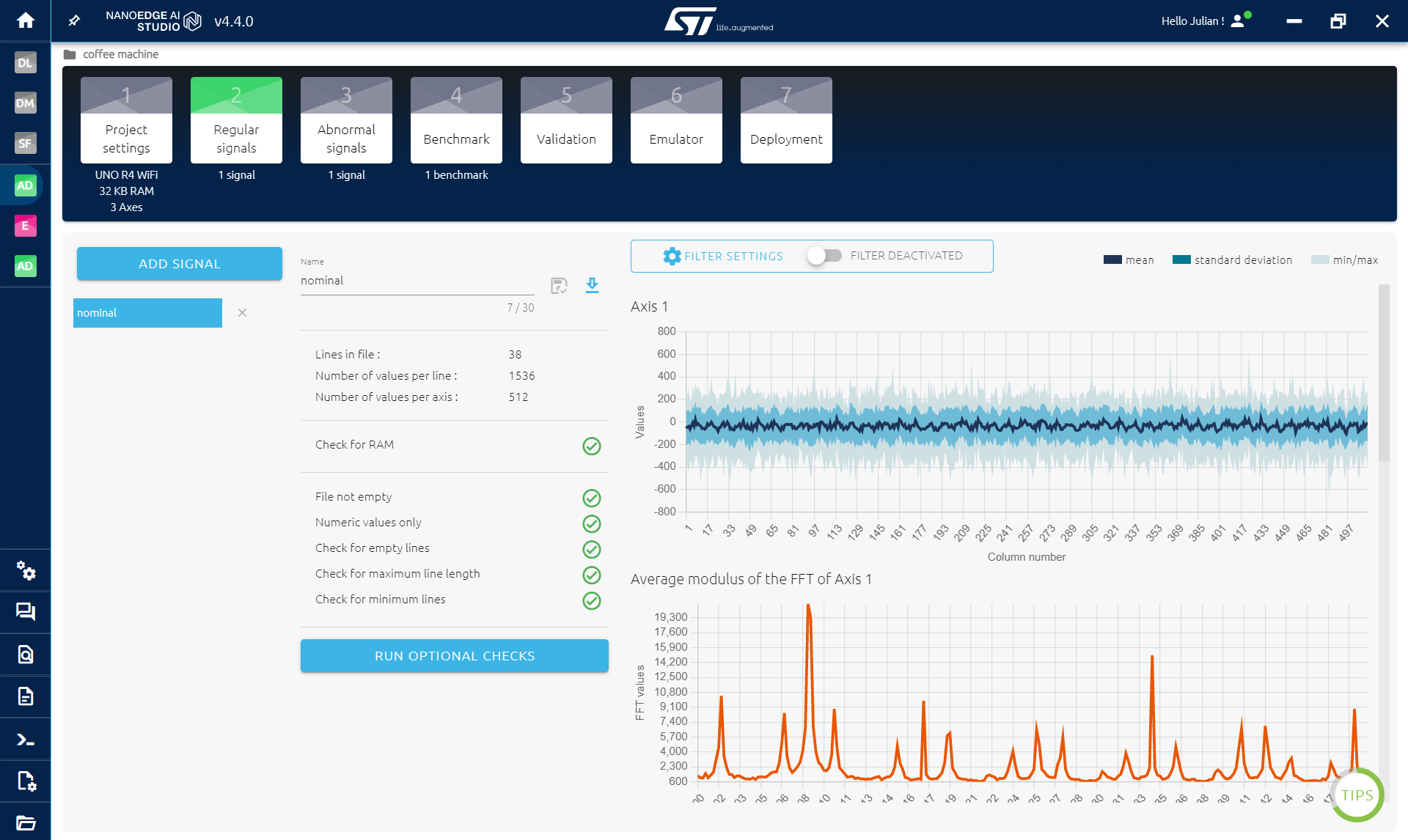
ในส่วน Abnormal signals: ทำแบบเดียวกัน แต่ทำตอนที่น้ำไม่พอหรือไม่มีน้ำเลยสำหรับชงกาแฟ
ขั้นตอน Benchmark: ตอนนี้เรามีข้อมูล 2 แบบแล้ว เราสามารถให้ NanoEdge AI Studio นำข้อมูลนี้ไปสร้าง AI Library ซึ่งประกอบด้วยโมเดล พารามิเตอร์ และการประมวลผลล่วงหน้า (เช่น FFT) ให้เราได้ คลิกที่ new benchmark เลือกข้อมูลทั้งสองประเภท แล้วคลิก start ระหว่างทำ benchmark โปรแกรมจะทดสอบการผสมผสานหลายแสนแบบเพื่อหาสูตรที่ดีที่สุดสำหรับข้อมูลที่เราให้ คะแนนที่ได้คือตัวชี้วัดที่คำนึงถึงความแม่นยำโดยรวมของโมเดล และการใช้ RAM กับ FLASH พอได้ความแม่นยำ 90% ขึ้นไป ก็หยุด benchmark ได้เลย มันอาจใช้เวลาหลายชั่วโมงเพื่อหาไลบรารี่ที่เหมาะสมที่สุด แต่สำหรับเรา ถ้ามีอันที่ใช้การได้ก็พอแล้วจ้า
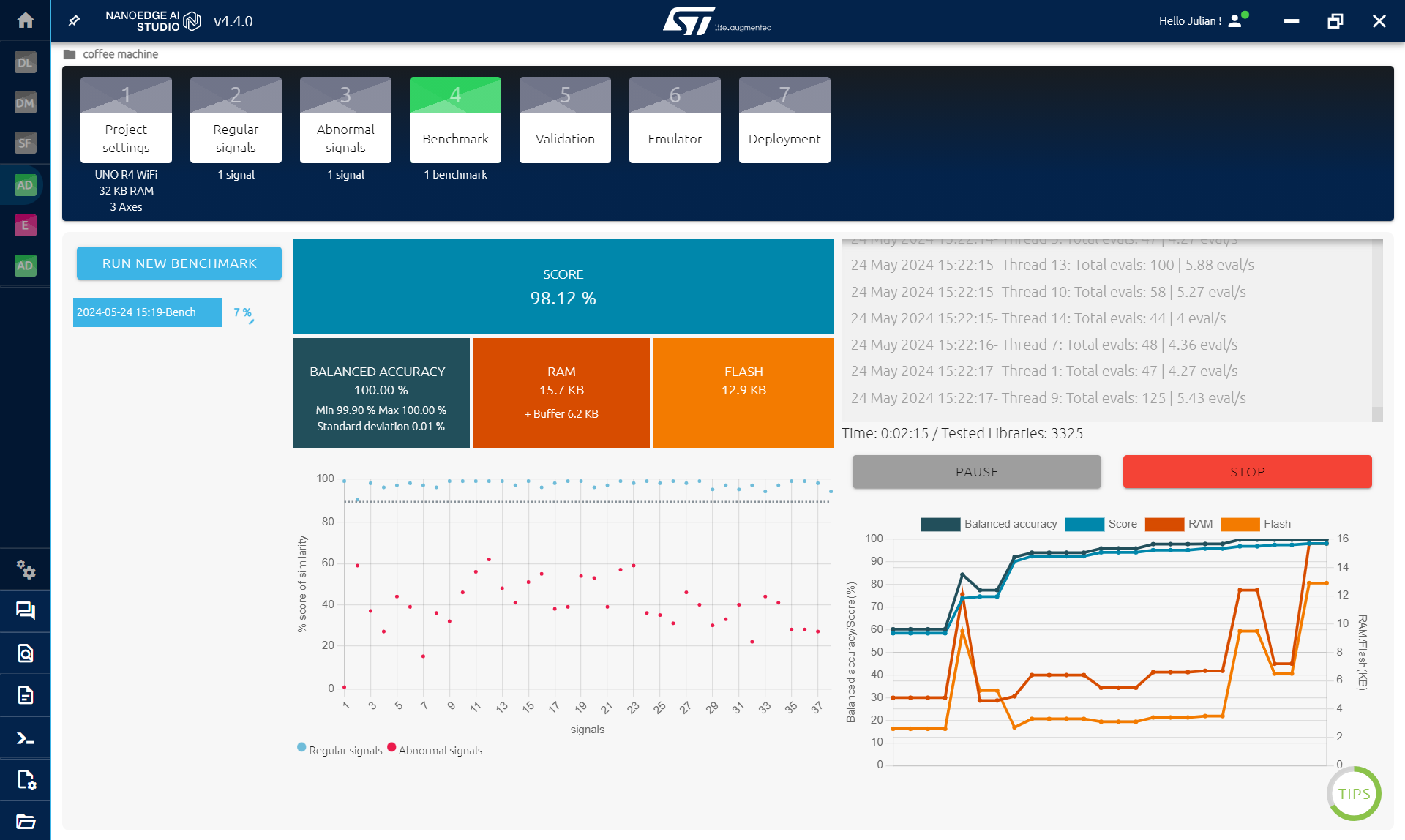
การตรวจสอบความถูกต้อง (Validation): เป้าหมายของขั้นนี้คือการทดสอบว่าโมเดลที่เราเจอตอนทำเบนช์มาร์กเนี่ย ยังเวิร์คกับข้อมูลใหม่รึเปล่า สิ่งที่อาจเกิดขึ้นกับโมเดล AI ก็คือมัน "โอเวอร์ฟิตติ้ง" (Overfitting) หมายความว่าโมเดลมันท่องจำข้อมูลเอาไว้เลย ไม่ได้เรียนรู้วิธีแยกแยะข้อมูลจริงๆ สิ่งที่ตามมาก็คือมันจะทำงานได้ห่วยแตกกับข้อมูลที่มันไม่เคยเห็นมาก่อน เลือกโมเดลที่ดีที่สุด 5 ตัว คลิกที่ New Experiment แล้วเพิ่มไฟล์ข้อมูลใหม่เข้าไป:
- ไฟล์เรียนรู้ (Learn files): โมเดลตรวจจับความผิดปกติของ NanoEdge สามารถฝึกใหม่ได้เลยบนไมโครคอนโทรลเลอร์ ซึ่งมักจะให้ผลลัพธ์ที่ดีกว่าด้วยซ้ำ ตรงนี้เราสามารถนำเข้าไฟล์ปกติที่ใช้ในขั้นตอนปกติได้เลย (สามารถดาวน์โหลดไฟล์นั้นได้)
- ไฟล์ปกติ (Regular files): เราต้องการนำเข้าไฟล์ใหม่ที่มีสัญญาณปกติใหม่ๆ (ถ้าอยากได้ ก็ย้อนกลับไปขั้นตอนปกติ บันทึกข้อมูลใหม่ แล้วดาวน์โหลดไฟล์มาได้เลย)
- ไฟล์ผิดปกติ (Abnormal files): เหมือนกัน แต่เป็นสัญญาณผิดปกติใหม่ๆ รอสักพัก เราก็จะได้ค่าความแม่นยำใหม่สำหรับโมเดลทั้ง 5 ตัวที่เลือกไว้ ค่าความแม่นยำควรจะใกล้เคียงกับที่ได้ตอนทำเบนช์มาร์ก ถ้าไม่ใช่ล่ะก็ กลับไปทำเบนช์มาร์กใหม่ด้วยข้อมูลที่มากขึ้นซะ
การคอมไพล์ (Compilation): ตรงนี้เรามีทางเลือก 2 ทาง:
- ใช้โมเดลที่ฝึกไว้ตอนทำเบนช์มาร์กเลย
- ใช้โมเดลนั้น แต่ฝึกมันใหม่บนไมโครคอนโทรลเลอร์โดยตรง ถ้าไม่อยากฝึกใหม่ ก็แค่คลิก Compile เลย ถ้าอยากให้โมเดลมีความรู้จากเบนช์มาร์กติดไปด้วย ให้ติ๊กถูกที่ช่อง "Include knowledge from benchmark" ก่อนคอมไพล์ เดี๋ยวในบทเรียนนี้เราจะเปลี่ยนโค้ดแค่ไม่กี่บรรทัดเท่านั้น
วิศวกรรมและการนำไปใช้ (Engineering & Implementation)
- การวินิจฉัยความสมบูรณ์ของโครงสร้าง (Structural Integrity Diagnostics):
- การติดตั้งแบบไม่บุกรุก (Non-Intrusive Mounting): โหนดเซ็นเซอร์ถูกยึดเข้ากับโครงเครื่องโดยใช้พันธะเชิงความร้อน-กลศาสตร์ที่มีการยึดติดสูง (เช่น Blu Tack หรือแผ่นกาว) การยึดคัปปลิ้งนี้สำคัญมากสำหรับการส่งผ่านพลังงานเสียงจากปั๊มไปยัง ST X-NUCLEO shield ได้อย่างแม่นยำ
- การวิเคราะห์การจัดการบัฟเฟอร์ (Buffer-Management Forensics): เฟิร์มแวร์ใช้ลูปโพลลิงแบบกำหนดได้ (deterministic polling loop) ถ้าคะแนนความคล้ายคลึง (similarity score) เบี่ยงเบนจากค่าฐานที่ฝึกไว้ ผ่านหลายๆ บัฟเฟอร์ ระบบก็จะยืนยันสถานะ "ตรวจพบความผิดปกติ (Anomaly Detected)" ซึ่งช่วยกำจัดสัญญาณเตือนผิดพลาดที่เกิดจากแรงกระทบภายนอกโดยบังเอิญ (เช่น การปิดตู้ครัว) ได้
- ลอจิกโฟลว์ของ HMI (HMI Logic Flow):
- การนำไปใช้มีสองเฟสการทำงาน: โหมด 0 (บันทึกข้อมูล - Datalogging) สำหรับสร้างค่าฐาน และ โหมด 1 (ตรวจจับ - Detection) สำหรับการอนุมานแบบเรียลไทม์ การแยกส่วนลอจิกแบบนี้ทำให้มั่นใจได้ว่า "ฐานความรู้ (Knowledge Base)" ของ AI จะถูกเติมด้วยข้อมูลที่มีสัญญาณต่อสัญญาณรบกวนสูง (High-SNR) ก่อนที่จะนำไปใช้งานจริง
ขั้นตอนที่ 4: เพิ่ม NanoEdge ลงในโค้ด Arduino
ตอนนี้เรามีไลบรารีตรวจจับความผิดปกติแล้ว ต่อไปก็ต้องเพิ่มมันลงในโค้ด Arduino ของเรา:
- เปิดไฟล์ .zip ที่ได้มา จะมีโฟลเดอร์ Arduino ที่ข้างในมี zip อีกอันหนึ่ง
- นำเข้าไลบรารีใน Arduino IDE: Sketch > Include library > Add .ZIP library... แล้วเลือกไฟล์ .zip ที่อยู่ในโฟลเดอร์ Arduino
ถ้าใช้ไลบรารี NanoEdge AI ใน Arduino IDE อยู่แล้ว: ไปที่ document/arduino/library แล้วลบไลบรารีตัวเก่าของ NanoEdge ออก จากนั้นทำตามขั้นตอนด้านบนเพื่อนำเข้าไลบรารีตัวใหม่
สำคัญมาก: ถ้าเจอข้อผิดพลาดเกี่ยวกับ RAM มันอาจเป็นเพราะไลบรารีที่เลือกใน NanoEdge ใหญ่เกินไป ให้กลับไปที่ขั้นตอน VALIDATION STEP ใน NanoEdge แล้วเลือกไลบรารีที่เล็กกว่า (คลิกที่มงกุฎทางขวา) จากนั้นคอมไพล์ใหม่แล้วเอามาแทนที่ใน Arduino IDE
ตัวเลือก A: ฝึกโมเดลใหม่
ในโค้ดที่เราใช้สำหรับบันทึกข้อมูล แค่เปลี่ยน NEAI_MODE เป็น 1 และเอา comment ออกจากโค้ดส่วนนี้:
...
#include <NanoEdgeAI.h>
...
#define NEAI_MODE 1 //0 คือโค้ดบันทึกข้อมูล, 1 คือโค้ดตรวจจับ
...
void setup(){
...
neai_code = neai_anomalydetection_init(); //initialisation
if(neai_code != NEAI_OK) {
Serial.print("Not supported board.\n");
}
}
void loop(){
...
if(NEAI_MODE) {
if(neai_cnt < MINIMUM_ITERATION_CALLS_FOR_EFFICIENT_LEARNING) {
neai_anomalydetection_learn(neai_buffer);
Serial.print((String)"Learn: " + neai_cnt + "/" + MINIMUM_ITERATION_CALLS_FOR_EFFICIENT_LEARNING + ".\n");
neai_cnt++; } else { neai_anomalydetection_detect(neai_buffer, &similarity); Serial.print((String)"Detect: " + similarity + "/100.\n"); } } }
**ตัวเลือก B: ใช้ความรู้ (knowledge) จากขั้นตอนเบนช์มาร์ค**
ถ้าน้องตัดสินใจแล้วว่าจะใช้ความรู้จากขั้นตอนเบนช์มาร์ค ตามนี้เลย:
1. ในส่วน `init()` ของโค้ด ให้เพิ่มบรรทัดนี้เข้าไป: `neai_anomalydetection_knowledge(knowledge);`
2. ใน `loop()` หลัง `if(NEAI_MODE)` ให้ลบ `if` statement พร้อมกับ `else {` และ `}` ออกไปซะ
#include <NanoEdgeAI.h> #include "knowledge.h" // อย่าลืมโหลดความรู้ด้วยน้อง!
void setup(){ ... neai_code = neai_anomalydetection_init(); if (neai_code != NEAI_OK) { Serial.print("Not supported board.\n"); } else { neai_anomalydetection_knowledge(knowledge); // โค้ดบรรทัดนี้แหละที่โหลดความรู้เข้าไป } } void loop(){ ... if(NEAI_MODE) { // ไม่มีส่วนเรียนรู้แล้วนะ แต่ส่วนตรวจจับยังเหมือนเดิม neai_anomalydetection_detect(neai_buffer, &similarity); Serial.print((String)"Detect: " + similarity + "/100.\n"); } ... }
ฟังก์ชัน `neai_anomalydetection_detect()` นี่แหละคือส่วนที่ใช้โมเดล AI ของเราตรวจจับ
ถ้า `similarity` เป็น 100 แปลว่าสัญญาณที่วัดได้เหมือนกับข้อมูลปกติ (น้ำเต็ม) 100% ถ้าเป็น 0 ก็คือมีโอกาส 0% ที่จะเป็นข้อมูลปกติ
ในโค้ดตั้งต้นเราแค่พิมพ์ค่าความคล้ายออกมา น้องสามารถเขียน `if` statement ขึ้นมาเองได้ เช่น ถ้าค่ามากกว่า 90 ให้พิมพ์ "OK" ถ้าน้อยกว่านั้นให้บอกว่า "เติมน้ำหน่อยยย" ตามสไตล์น้องเลย:
if (similarity > 90){
Serial.print("OK");
} else {
Serial.print("Not enough water, please add water");
}
### สรุปสั้นๆ
โปรเจค Coffee-Sense นี้คือคลาสเรียนระดับมาสเตอร์ในเรื่อง **Predictive Embedded Engineering** เลยนะเว้ย! การที่เราชำนาญเรื่อง **Edge-AI Vibrational Forensics** และ **Accelerometer Diagnostics** ทำให้โปรเจคนี้กลายเป็นโซลูชันระดับโปรสำหรับการดูแลเครื่องใช้ไฟฟ้า มันพิสูจน์ให้เห็นว่าเราสามารถใช้ซอฟต์แวร์อัจฉริยะแทนเซ็นเซอร์กลไกซับซ้อนในระบบสมาร์ทโฮมยุคใหม่ได้สบายๆ
---
*Predictive Precision: Mastering appliance maintenance through Edge-AI forensics.*
---
จัดไปวัยรุ่น! สู้งานนะน้อง