🏆 TensorFlow Lite for Microcontrollers Challenge 🏆

ผู้ชนะของ TensorFlow Lite for Microcontrollers Challenge ได้รับการประกาศเมื่อวันที่ 18 ตุลาคม 2021 โครงการนี้เป็นหนึ่งในห้าผู้ชนะทั่วโลกและได้รับการนำเสนอในเว็บไซต์ Experiments with Google
แนวคิด
แนวปฏิบัติที่ดีที่ควรพิจารณาขณะอยู่ในการจราจรคือการเตือนผู้ใช้ถนนคนอื่นๆ ถึงทิศทางที่คุณจะไป ก่อนจะเลี้ยวหรือเปลี่ยนเลน นิสัยนี้ช่วยให้การจราจรไหลลื่นขึ้นและลดการเคลื่อนไหวกะทันหันจากผู้ขับขี่ที่ไม่ทราบสถานการณ์ ที่จริงแล้ว รถยนต์ รถจักรยานยนต์ รถบรรทุก รถโดยสาร และยานพาหนะส่วนใหญ่ที่คุณนึกถึง ล้วนมีอุปกรณ์สัญญาณไฟเลี้ยวในตัว
แม้ว่าจักรยานจะจัดเป็นยานพาหนะที่เปราะบางที่สุดบนท้องถนน แต่โดยปกติแล้วจักรยานมักไม่มีอุปกรณ์สัญญาณไฟเลี้ยวในตัวแบบนั้น ผู้ขี่จักรยานมักไม่เตือนว่าจะเลี้ยว หรือถ้าทำ ก็ต้องปล่อยมือจากแฮนด์จับเพื่อทำสัญญาณให้ผู้ขับขี่คนอื่นเห็น การเคลื่อนไหวนี้ลดความมั่นคงของผู้ขี่ และอาจไม่ได้รับการเข้าใจที่ถูกต้องจากทุกคน
ในตลาดสามารถหาไฟสัญญาณเลี้ยวเสริมสำหรับจักรยานได้ แต่โดยทั่วไปแล้วผู้ขี่ต้องกดปุ่มเพื่อเปิดใช้งานและกดอีกครั้งเพื่อปิด คล้ายกับรถจักรยานยนต์ และมันง่ายมากที่จะลืมปิดไฟ หากลองคิดดูดีๆ นี่คือสิ่งที่ควรได้รับการปรับปรุง
จากจุดนี้เองที่ VoiceTurn ได้ถือกำเนิดขึ้น ซึ่งเป็นแนวคิดไฟสัญญาณเลี้ยวควบคุมด้วยเสียงที่คิดขึ้นมาในตอนแรกสำหรับจักรยาน แต่สามารถขยายไปสู่ยานพาหนะอื่นๆ ได้เช่นกัน เป้าหมายของโครงการนี้คือการใช้อัลกอริทึม Machine Learning เพื่อสอนไมโครคอนโทรลเลอร์ขนาดเล็กให้เข้าใจคำว่า left! และ right! และดำเนินการตามนั้นโดยเปิดไฟสัญญาณเลี้ยวด้านที่เกี่ยวข้อง
บอร์ด
บอร์ดไมโครคอนโทรลเลอร์ที่จะใช้คือ Arduino Nano 33 BLE Sense: บอร์ดราคาประหยัดที่มี CPU 32-bit ARM® Cortex™-M4 ทำงานที่ความถี่ 64 MHz, เซนเซอร์ในตัวหลายชนิด รวมถึงไมโครโฟนดิจิทัล และการเชื่อมต่อ Bluetooth Low Energy (BLE)
อย่างไรก็ตาม สิ่งที่ทำให้บอร์ดนี้เป็นตัวเลือกที่ยอดเยี่ยมสำหรับโครงการนี้คือความสามารถในการรันแอปพลิเคชัน Edge Computing บนบอร์ดโดยใช้ Tiny Machine Learning (TinyML) กล่าวโดยสรุป หลังจากสร้างโมเดล Machine Learning ด้วย TensorFlow Lite แล้ว คุณสามารถอัปโหลดโมเดลเหล่านั้นไปยังบอร์ดได้อย่างง่ายดายโดยใช้ Arduino Integrated Development Environment (IDE)
การรู้จำเสียงที่ Edge ไม่จำเป็นต้องส่งสตรีมเสียงไปยังเซิร์ฟเวอร์คลาวด์เพื่อประมวลผล จึงช่วยขจัดความล่าช้าของเครือข่าย นอกจากนี้ยังทำงานแบบออฟไลน์ ดังนั้นคุณจึงมั่นใจได้ว่าไฟสัญญาณเลี้ยวของคุณจะไม่หยุดทำงานเมื่อผ่านอุโมงค์ และสุดท้ายแต่ไม่ท้ายสุด มันปกป้องความเป็นส่วนตัวของผู้ใช้ เนื่องจากเสียงของคุณไม่ถูกเก็บหรือส่งไปที่ใด
ฝึกโมเดล Machine Learning
โมเดลการรู้จำคำถูกสร้างขึ้นโดยใช้ Edge Impulse ซึ่งเป็นแพลตฟอร์มพัฒนาสำหรับ Machine Learning บนอุปกรณ์ฝังตัว โดยมุ่งเน้นที่การมอบประสบการณ์ผู้ใช้ (UX) ที่ยอดเยี่ยม เอกสารประกอบที่ครบถ้วน และชุดพัฒนาซอฟต์แวร์ (SDKs) แบบโอเพนซอร์ส เว็บไซต์ของพวกเขาระบุว่า:
Edge Impulse ได้รับการออกแบบสำหรับนักพัฒนาซอฟต์แวร์ วิศวกร และผู้เชี่ยวชาญในสาขาต่างๆ เพื่อแก้ไขปัญหาจริงโดยใช้แมชชีนเลิร์นนิงบนอุปกรณ์เอดจ์ โดยไม่จำเป็นต้องมีปริญญาเอกด้านแมชชีนเลิร์นนิง
นั่นหมายความว่า คุณสามารถมีความรู้เกี่ยวกับแมชชีนเลิร์นนิงน้อยมากหรือไม่มีเลย และยังคงพัฒนาแอปพลิเคชันของคุณได้สำเร็จ
คุณสามารถใช้บทช่วยสอนนี้เป็นจุดเริ่มต้นสำหรับการจำแนกเสียงด้วย Edge Impulse ขั้นตอนต่อไปจะอธิบายว่าโครงการนี้ได้รับการปรับแต่งอย่างไรเพื่อตอบสนองความต้องการเฉพาะของ VoiceTurn
สิ่งแรกที่คุณต้องทำคือสมัครใช้งานบน Edge Impulse เพื่อ สร้างบัญชีผู้พัฒนาฟรี หลังจากขั้นตอนยืนยันบัญชีแล้ว ให้เข้าสู่ระบบและ สร้างโปรเจกต์ คุณจะได้รับตัวช่วยสร้างที่ถามเกี่ยวกับประเภทของโปรเจกต์ที่คุณต้องการสร้าง คลิกที่ Audio:

ในขั้นตอนต่อไป คุณสามารถเลือกจากสามตัวเลือก ตัวเลือกแรกคือการสร้างชุดข้อมูลเสียงแบบกำหนดเองด้วยตัวเองโดยเชื่อมต่อบอร์ดพัฒนาที่มีไมโครโฟน กระบวนการนี้จำเป็นต้องบันทึกข้อมูลเสียงจำนวนมากเพื่อให้ได้ผลลัพธ์ที่ยอมรับได้ ดังนั้นเราจะข้ามไปก่อน ตัวเลือกที่สองคือการอัปโหลดชุดข้อมูลเสียงที่มีอยู่ และตัวเลือกที่สามคือการทำตามบทช่วยสอน คลิกที่ Go to the uploader, ภายใต้ตัวเลือก Import existing data เพื่อดำเนินการต่อกับ VoiceTurn

ชุดข้อมูลเสียงที่เราจะใช้คือ Google Speech Commands Dataset ซึ่งประกอบด้วยเสียงพูดคำสั้นๆ 30 คำ ความยาว 1 วินาที จำนวน 65,000 รายการ จากผู้คนหลายพันคนที่แตกต่างกัน คุณสามารถ ดาวน์โหลดเวอร์ชัน 2 ของชุดข้อมูลนี้ ได้จากลิงก์นี้
อาจคิดได้ว่าเฉพาะชุดย่อยของเสียงบันทึกที่ตรงกับคำว่า left และ right เท่านั้นที่จำเป็นสำหรับการฝึกโมเดล อย่างไรก็ตาม ตามที่ Pete Warden จาก Google Brain ระบุไว้ในบทความที่อธิบายวิธีการที่ใช้ในการรวบรวมและประเมินชุดข้อมูล:
ข้อกำหนดสำคัญสำหรับการตรวจจับคำหลักในผลิตภัณฑ์จริงคือความสามารถในการแยกแยะระหว่างเสียงที่มีคำพูด และคลิปที่ไม่มีคำพูด
ดังนั้น เราจะใช้ชุดย่อยของเสียงบันทึกที่อยู่ในโฟลเดอร์ _background_noise_ ด้วย เพื่อเพิ่มความหลากหลายให้กับโมเดลของเราด้วยเสียงพื้นหลังบางส่วน นอกจากนี้ เราจะเสริมฐานข้อมูลเสียงรบกวนด้วยไฟล์เสียงจากโฟลเดอร์ noise จากชุดข้อมูลสำเร็จรูป "Keyword spotting" ที่มีอยู่ในเอกสารประกอบของ Edge Impulse
การมีชุดข้อมูลที่มีคำว่า left และ right และเสียงพื้นหลังบางส่วนยังไม่เพียงพอ เนื่องจากเรายังต้องให้โมเดลมีคำเพิ่มเติมด้วย วิธีนี้ หากได้ยินคำอื่น มันจะไม่ถูกจำแนกว่าเป็น left หรือ right แต่จะถูกจัดอยู่ในหมวดหมู่อื่น ในการทำเช่นนั้น เราสามารถเลือกชุดเสียงบันทึกแบบสุ่มจากชุดข้อมูลแรกที่เราดาวน์โหลดมา เพียงสังเกตว่าจำนวนเสียงบันทึกเพิ่มเติมทั้งหมดควรใกล้เคียงกับจำนวนเสียงบันทึกทั้งหมดของแต่ละคำที่เราสนใจ
เมื่อรวบรวมเสียงบันทึกแล้ว ให้อัปโหลดลงในโปรเจกต์ Edge Impulse ของคุณ โปรดทราบว่าคุณจะต้องอัปโหลดชุดข้อมูลที่แตกต่างกัน 4 ชุด แต่ละชุดสอดคล้องกับหมวดหมู่ที่ต่างกัน เรียกดูไฟล์ของคุณ ป้อนป้ายกำกับด้วยตนเอง ได้แก่ Left, Right, noise และ other ตามลำดับ และตรวจสอบให้แน่ใจว่าเลือก Automatically split between training and testing แล้ว ซึ่งจะกันตัวอย่างประมาณ 20% ไว้สำหรับทดสอบโมเดลในภายหลัง คลิกที่ Begin upload
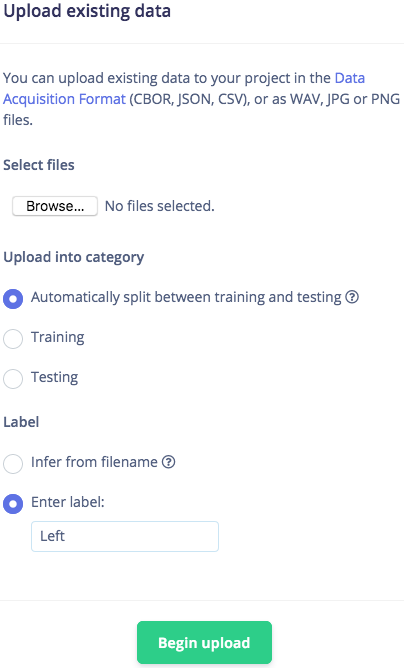
คุณจะสังเกตเห็นว่าไฟล์เสียงตัวอย่างทั้งหมดที่คุณอัปโหลดสามารถตรวจสอบและฟังได้ ตรวจสอบให้แน่ใจว่าทุกไฟล์มีความยาวหนึ่งวินาที หากไฟล์ยาวกว่านั้น ให้คลิกจุดสามจุดทางด้านขวาของแถวไฟล์เสียง แล้วคลิกที่ Split sample โดยกำหนดความยาวของเซกเมนต์เป็น 1000 มิลลิวินาที
ผลลัพธ์ที่ได้ คุณควรจะเห็นระยะเวลารวมของข้อมูลสำหรับการฝึกฝนและทดสอบ ตามลำดับ พร้อมกับข้อมูลของคุณที่ถูกแบ่งออกเป็นสี่หมวดหมู่:
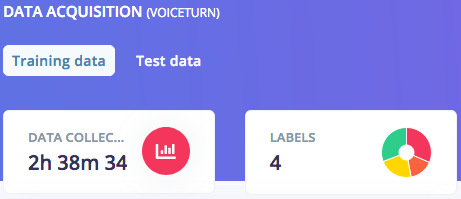
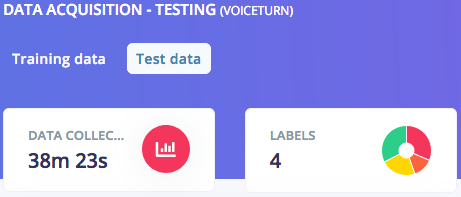
คุณยังสามารถตรวจสอบอีกครั้งได้ว่าความยาวของข้อมูลสำหรับทดสอบนั้นมีค่าประมาณ 20% ของความยาวรวมของชุดข้อมูล
ขั้นตอนต่อไปคือ ออกแบบอิมพัลส์ (Impulse) ซึ่งคือชุดการดำเนินการทั้งหมดที่กระทำกับข้อมูลเสียงนำเข้า จนกระทั่งคำต่างๆ ถูกจำแนกประเภท คลิกที่ Create Impulse ในเมนูด้านซ้าย อิมพัลส์ของเราจะประกอบด้วยบล็อกนำเข้าเพื่อแบ่งข้อมูล บล็อกประมวลผลเพื่อเตรียมข้อมูล และบล็อกการเรียนรู้เพื่อจำแนกข้อมูลออกเป็นหนึ่งในสี่ป้ายกำกับที่กำหนดไว้ก่อนหน้านี้ คลิกที่ Add an input block และ เพิ่มบล็อก Time series data โดยตั้งค่าขนาดหน้าต่างเป็น 1000 มิลลิวินาที จากนั้นคลิกที่ Add a processing block และ เพิ่มบล็อก Audio Mel Frequency Cepstral Coefficients (MFCC) ซึ่งเหมาะสำหรับข้อมูลเสียงพูดของมนุษย์ บล็อกนี้จะสร้างรูปแบบที่เรียบง่ายของข้อมูลนำเข้า เพื่อให้บล็อกถัดไปประมวลผลได้ง่ายขึ้น สุดท้าย คลิกที่ Add a learning block และ เพิ่มบล็อก Classification (Keras) ซึ่งคือโครงข่ายประสาทเทียม (Neural Network) ที่ทำหน้าที่จำแนกประเภทและให้ผลลัพธ์
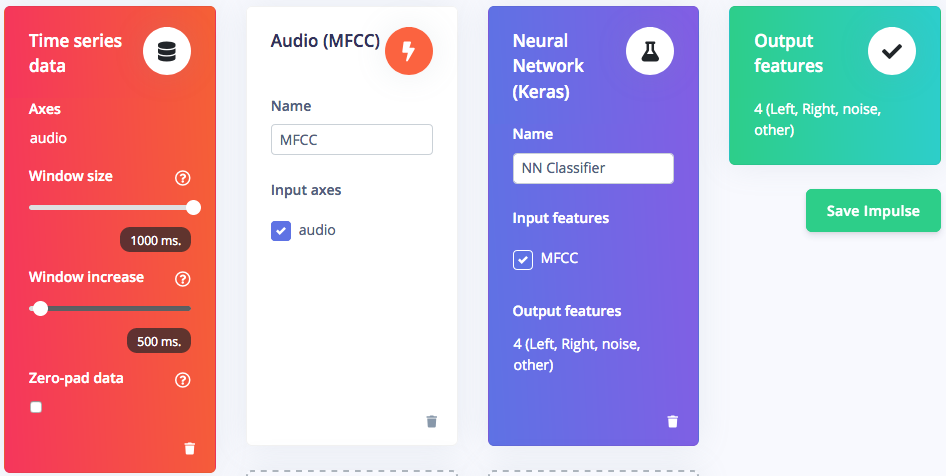
คุณสามารถกำหนดค่าทั้งบล็อกประมวลผลและบล็อกการเรียนรู้ได้ คลิกที่ MFCC ในเมนูด้านซ้าย และคุณจะเห็นพารามิเตอร์ทั้งหมดที่เกี่ยวข้องกับขั้นตอนการประมวลผลสัญญาณ ในโปรเจกต์นี้ เราจะทำให้สิ่งต่างๆ เรียบง่ายและใช้พารามิเตอร์เริ่มต้นของบล็อกนี้ คลิกที่ Generate features ด้านบน จากนั้นคลิกปุ่ม Generate features เพื่อสร้างบล็อก MFCC ที่สอดคล้องกับหน้าต่างเสียง หลังจากงานเสร็จสิ้น คุณจะเห็น Feature explorer ซึ่งเป็นการแสดงข้อมูลชุดข้อมูลของคุณในรูปแบบ 3 มิติ เครื่องมือนี้มีประโยชน์สำหรับการตรวจสอบอย่างรวดเร็วว่าตัวอย่างของคุณแยกออกจากกันได้ดีตามหมวดหมู่ที่คุณกำหนดไว้ก่อนหน้านี้หรือไม่ เพื่อให้ชุดข้อมูลของคุณเหมาะสมสำหรับการเรียนรู้ของเครื่อง บนหน้านี้คุณยังสามารถเห็นการประมาณเวลาที่ขั้นตอนการประมวลผลสัญญาณข้อมูล (Data Signal Processing - DSP) จะใช้ในการประมวลผลข้อมูลของคุณ รวมถึงการใช้หน่วยความจำ RAM เมื่อรันบนไมโครคอนโทรลเลอร์
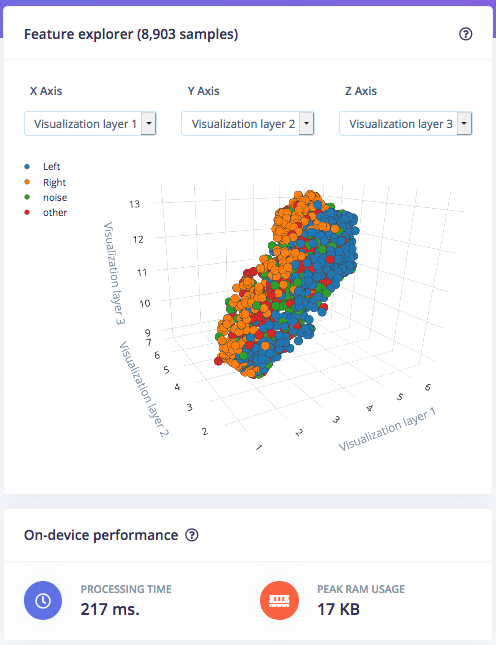
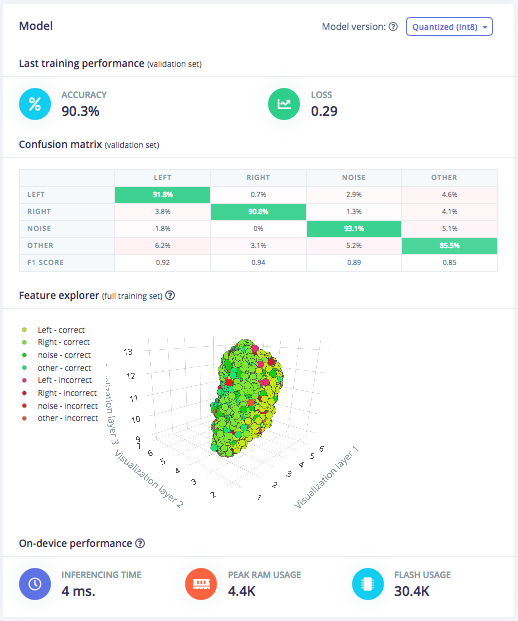
ตอนนี้คุณสามารถคลิกที่ NN Classifier ในเมนูด้านซ้ายและเริ่มฝึกฝนโครงข่ายประสาทเทียมของคุณ ซึ่งเป็นชุดอัลกอริทึมที่สามารถจดจำรูปแบบในข้อมูลการเรียนรู้ได้ โครงข่ายประสาทเทียมมีหลักการทำงานและมีการใช้งานที่หลากหลาย เราจะปล่อยให้การตั้งค่า Neural Network settings ส่วนใหญ่เป็นค่าเริ่มต้น แต่จะเพิ่มค่า Minimum confidence rating เล็กน้อยเป็น 0.7 ซึ่งหมายความว่าในระหว่างการฝึกฝน จะพิจารณาเฉพาะการทำนายที่มีความน่าจะเป็นของความมั่นใจสูงกว่า 70% เท่านั้นว่าใช้ได้ เปิดใช้งาน Data augmentation และตั้งค่า Add noise เป็น High เพื่อทำให้โครงข่ายประสาทเทียมของเรามีความแข็งแกร่งมากขึ้นในสถานการณ์จริง คลิกที่ Start training ที่ด้านล่างของหน้า เมื่อการฝึกฝนเสร็จสิ้น คุณจะเห็นความแม่นยำของโมเดล ซึ่งคำนวณโดยใช้ชุดย่อย 20% ของข้อมูลการฝึกฝนที่จัดสรรไว้สำหรับการตรวจสอบ คุณยังสามารถตรวจสอบ Confusion matrix ซึ่งเป็นตารางที่แสดงความสมดุลระหว่างคำที่จำแนกถูกต้องกับคำที่จำแนกผิดพลาด และการประมาณ on-device performance ได้อีกด้วย
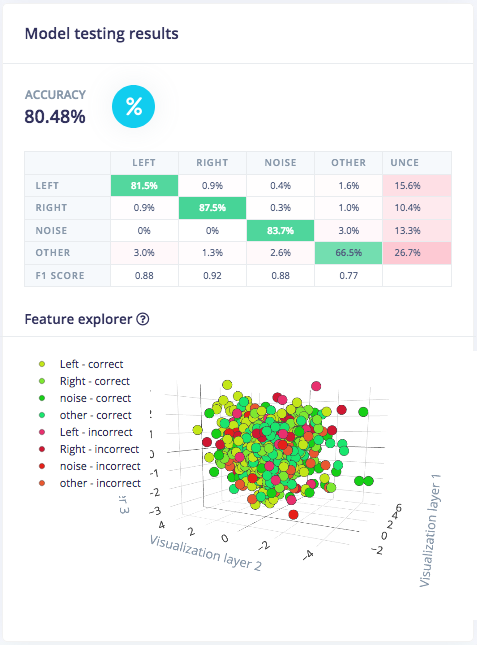
ตอนนี้คุณสามารถทดสอบโมเดลที่เพิ่งฝึกเสร็จด้วยข้อมูลใหม่ได้ เป็นไปได้ที่จะเชื่อมต่อบอร์ด Arduino กับ Edge Impulse เพื่อทำการจำแนกประเภทข้อมูลแบบสด (live classification) อย่างไรก็ตาม เราจะ ทดสอบโมเดล โดยใช้ข้อมูลทดสอบที่เราแยกไว้ในขั้นตอน การรวบรวมข้อมูล (Data acquisition) คลิกที่ Model testing ในเมนูด้านซ้าย จากนั้นคลิกที่ Classify all เพื่อทดสอบข้อมูลทั้งหมด คุณจะได้รับผลตอบรับเกี่ยวกับประสิทธิภาพของโมเดลของคุณ นอกจากนี้ Feature explorer จะช่วยให้คุณตรวจสอบได้ว่ามีอะไรเกิดขึ้นกับตัวอย่างที่ไม่ถูกจำแนกประเภทอย่างถูกต้อง เพื่อที่คุณจะสามารถติดป้ายกำกับใหม่ได้หากจำเป็น หรือย้ายกลับไปยังส่วนการฝึกเพื่อปรับแต่งโมเดลของคุณให้ดีขึ้น
สุดท้าย คุณสามารถสร้างไลบรารีที่บรรจุโมเดลของคุณและพร้อมที่จะนำไปใช้งานบนไมโครคอนโทรลเลอร์ได้ คลิกที่ Deployment ในเมนูด้านซ้าย เลือกสร้าง Arduino library และเลื่อนไปที่ด้านล่างของหน้า ที่นี่คุณสามารถเปิดใช้งาน EON™ Compiler เพื่อเพิ่มประสิทธิภาพบนอุปกรณ์ โดยแลกกับการลดความแม่นยำ อย่างไรก็ตาม เนื่องจากปริมาณการใช้หน่วยความจำสำหรับ Arduino Nano 33 BLE Sense ไม่สูงเกินไป เราจึงสามารถปิดตัวเลือกนี้ได้เพื่อทำงานด้วยความแม่นยำสูงสุดที่เป็นไปได้ สุดท้ายปล่อยให้ตัวเลือก Quantized (int8) ถูกเลือกไว้ และคลิกที่ปุ่ม Build เพื่อ ดาวน์โหลดไฟล์ .zip ที่บรรจุไลบรารีของคุณ
โปรเจกต์ VoiceTurn Edge Impulse นั้นเปิดให้เข้าถึงสาธารณะ ดังนั้นคุณสามารถโคลนและทำงานกับมันได้โดยตรงหากต้องการ
ตรวจสอบว่าคำถูกจำแนกประเภทอย่างไร
คุณสามารถใช้ Arduino IDE เพื่อนำไลบรารีที่สร้างด้วย Edge Impulse ไปใช้งานบนบอร์ดของคุณได้ หากคุณยังไม่ได้ติดตั้ง ให้ดาวน์โหลดเวอร์ชันล่าสุดจากหน้า Arduino software หลังจากนั้น คุณจะต้องเพิ่มแพ็คเกจไดรเวอร์ที่รองรับบอร์ด Arduino Nano 33 BLE Sense เปิด Arduino IDE และคลิกที่ Tools > Board > Boards Manager...
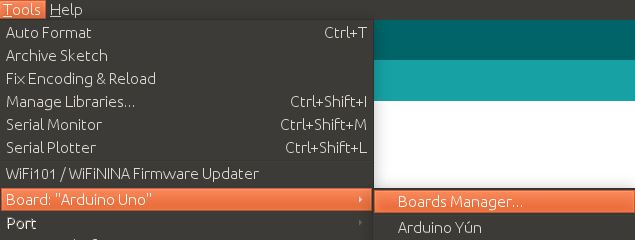
พิมพ์ nano 33 ble sense ในช่อง Search และ ติดตั้งแพ็คเกจ Arduino Mbed OS Nano Boards

ตอนนี้ IDE ของคุณพร้อมที่จะทำงานกับบอร์ดของคุณแล้ว เชื่อมต่อ Arduino Nano 33 BLE Sense ของคุณกับคอมพิวเตอร์ และตั้งค่าต่อไปนี้:
- คลิกที่ Tools > Board > Arduino Mbed OS Nano Boards และ เลือก Ar